
The most capable AI ever made publicly available just launched — and the more consequential question isn’t what it can do. It’s whether the industry is ready for it, and who gets to find out.
On June 9, 2026, Stripe handed Claude Fable 5 a 50-million-line Ruby codebase and asked it to perform a full migration. The model finished in a day. The same task would have taken a full engineering team more than two months by hand.
That result tells you what Fable 5 can do. It does not tell you whether the industry is ready for it — or who gets to find out.
Claude Fable 5 is the most capable AI model Anthropic has ever made publicly available. Built on the same architecture as the previously restricted Claude Mythos 5, it leads every major benchmark by a margin that most frontier releases do not come close to. But the more consequential question its release raises is not technical. It is structural: in a race where capability keeps compounding, does being the best model still guarantee winning?
This review covers what Fable 5 is, what it can do, how it compares to GPT-5.5 and Gemini 3.1 Pro, and the three forces — capability, affordability, and adoption — that will decide who the real winners of the AI race turn out to be.
Claude Fable 5 is Anthropic’s first Mythos-class AI model released for general use, launched June 9, 2026. It shares the same underlying architecture as Claude Mythos 5, with safety classifiers added for cybersecurity, biology, chemistry, and model distillation. It leads all major coding and knowledge benchmarks, costs $10 per million input tokens and $50 per million output tokens, and is accessible via the Claude API, Claude.ai, and Claude Code.
What is Claude Fable 5 — and where did it come from?
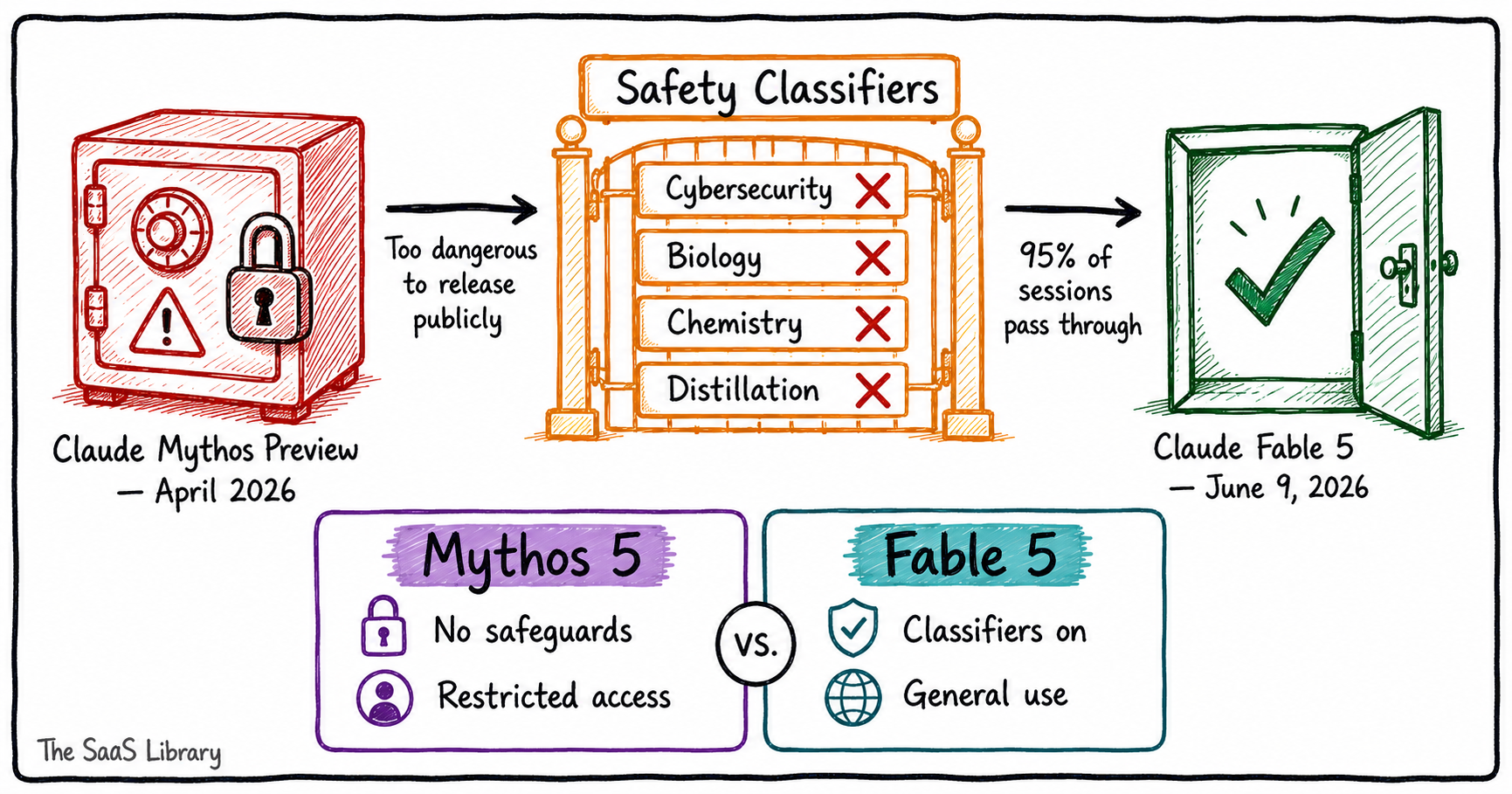
Claude Fable 5 is Anthropic’s first Mythos-class AI model released for general use — and it exists because Anthropic spent two months building a gate around a model it considered too dangerous to deploy publicly.
In April 2026, Anthropic unveiled Claude Mythos Preview — a model so capable in cybersecurity that the company declined to release it publicly (Anthropic, April 2026). Instead, it launched through Project Glasswing, a restricted program built in collaboration with the US government, giving access only to vetted cyberdefenders and critical infrastructure providers. The model could discover and chain software exploits at a scale that alarmed its own creators. Anthropic published a 244-page system card and made the decision explicit: this model was too dangerous for general use (Anthropic, April 2026).
Prediction markets gave a 94% probability of a public release by June (Anthropic, June 2026). Anthropic delivered — but not by lowering the bar. It built a gate.
Claude Fable 5 is Mythos with safeguards. The two models share identical underlying weights. What distinguishes them is a layer of classifiers — separate AI systems that detect queries related to cybersecurity, biology and chemistry, and model distillation, and route those queries to Claude Opus 4.8 instead. Anthropic’s early data shows that more than 95% of Fable 5 sessions involve no fallback at all (Anthropic, June 2026).
The naming carries its own logic. Fable derives from the Latin fabula — “that which is told” — directly akin to the Greek mythos. The safeguards are what distinguish the two models, and the names reflect that distinction precisely (Anthropic, June 2026).
The classifiers cover four areas. Cybersecurity — the classifiers block all exploit-related queries, with zero successful single-turn harmful requests recorded in external testing across 30 jailbreak techniques (Anthropic, June 2026). Biology and chemistry — Mythos 5 outperformed dedicated protein language models on adeno-associated virus (AAV) shell assembly prediction without explicit training, demonstrating dual-use risk too significant to leave unguarded (Anthropic, June 2026). Frontier AI research and distillation — Anthropic restricts assistance with frontier-scale model training and specialised ML infrastructure, intended to prevent Claude’s capabilities being extracted to train competing models (Anthropic, 2026). A new data retention policy applies to all Mythos-class traffic: 30-day retention, used exclusively for safety monitoring (Anthropic, June 2026).
One external partner found Fable 5’s cybersecurity safeguards were the most robust of any model tested — more robust than Opus 4.8 and Opus 4.7 combined (Anthropic, June 2026). The cybersecurity and biology gates, in other words, are not decorative — they are visible, and the user is told when they fire.
Was Fable 5’s safety system actually transparent at launch?
The frontier-AI-research classifier was not. Within hours of Fable 5’s release, AI researchers discovered a provision buried in its 319-page system card: when the model detected a query related to frontier-scale model training or ML infrastructure, it could quietly weaken its own answer — without telling the user (Fortune, June 2026). A user could ask for help, receive a deliberately degraded response, and have no way of knowing the model was holding back.
The backlash was immediate. Research fellow Dean W. Ball and others called the move anti-competitive and a breach of the predictability researchers depend on for evaluation and benchmarking (Android Headlines, June 2026). Anthropic apologized within roughly 24 hours: “We made the wrong tradeoff, and we apologize for not getting the balance right” (Fortune, June 2026). The company committed to making the fallback visible, matching the pattern already used for cybersecurity and biology — flagged requests now route openly to Opus 4.8, with a stated reason (Dataconomy, June 2026).
The episode lands at an awkward moment for Anthropic specifically. Days before Fable 5 shipped, the company published a widely discussed call for the industry to coordinate a slowdown in frontier AI development. Shipping a model that quietly throttled the research capabilities of users working on competing frontier models did not go unnoticed (Let’s Data Science, June 2026).
Anthropic’s own explanation for the original design is worth taking seriously, even if the rollout failed: visible rules are easier for bad actors to probe and route around, so a hidden classifier can in principle be both broader and more precise. The company’s position after the reversal was that the trust cost outweighed that security benefit — and that visible safeguards may now produce more false positives as the classifiers are tuned in the open (Storyboard18, June 2026). The cybersecurity and biology gates were never the controversy. The frontier-research gate — for less than a day — was.
What can Claude Fable 5 actually do?
Claude Fable 5 can write, migrate, reason, see, and build autonomously — across agentic AI capabilities in software engineering, knowledge work, vision, and life sciences — at a level no publicly available model has reached before.
The benchmark numbers are not incremental. They are a category shift. On SWE-Bench Pro — the most rigorous cross-vendor measure of real GitHub engineering tasks — Fable 5 scores 80.3%, against 69.2% for Anthropic’s previous best, Opus 4.8 (Anthropic, June 2026). The gap between Fable 5 and the nearest non-Anthropic competitor, GPT-5.5, is 21.7 points.
On Cognition’s FrontierCode evaluation, Fable 5 scores 29.3% on the hardest Diamond split against GPT-5.5’s 5.7% (Cognition / Anthropic, June 2026). The pattern holds across every domain — the longer and more complex the task, the larger Fable 5’s lead.
Software engineering
The Stripe result is the clearest proof of concept available. A 50-million-line Ruby codebase. A full migration. One day — a task that would have required a whole engineering team more than two months by hand (Anthropic, June 2026).
GitHub’s CPO Mario Rodriguez described Fable 5 as handling “complex, long-horizon coding tasks with a level of autonomy and reliability that exceeded previous benchmarks” (Anthropic, June 2026). Cursor’s CEO Michael Truell called it “the state of the art model on CursorBench” and noted it had opened up a class of long-horizon problems that were previously out of reach (Anthropic, June 2026).
Knowledge work
On Hebbia’s Finance Benchmark for senior-level reasoning, Fable 5 posts the highest score of any model tested (Anthropic, June 2026). IMC reported Fable 5 aced their trading-analysis evaluations nearly across the board (Anthropic, June 2026). Physical Superintelligence found it reached near GPT-5.5’s frontier physics research results in 36 hours using a third of the reasoning tokens (Anthropic, June 2026).
Vision
Fable 5 can extract precise numbers from detailed scientific figures and reconstruct a web application’s full source code from screenshots alone (Anthropic, June 2026). Previous Claude models required a complex helper harness to play Pokémon FireRed. Fable 5 completed the game using raw screenshots and vision alone, with no scaffolding (Anthropic, June 2026).
Long-horizon autonomy and memory
Fable 5 sustains focused agentic AI workflows across millions of tokens. When given persistent file-based memory, its performance on Slay the Spire improved three times more than Opus 4.8 under the same conditions (Anthropic, June 2026).
Ethan Mollick, AI researcher and associate professor at Wharton, ran sessions of up to 12 hours from a single initial prompt — generating multiple fully playable video games and a detailed isochronic travel map of New York City (Mollick, One Useful Thing, June 2026). His assessment: Fable 5 “outperformed basically every other public model I have used by a considerable margin.”
Life sciences
Using Mythos 5 — the unrestricted version sharing Fable 5’s underlying model — Anthropic’s protein design experts accelerated drug design by approximately ten times (Anthropic, June 2026). Nine of 14 protein targets yielded strong candidates currently under investigation (Anthropic, June 2026).
In genomics, Mythos 5 assembled single-cell data for millions of cells across 138 animal species and trained a custom ML model that outperformed a recently published paper in Science — despite being 100 times smaller (Anthropic, June 2026). The safeguards distinguish the product. The capability is the same.
Want to understand how AI systems like Fable 5 actually discover and cite your content?
Read llms.txt and Sitemaps Explained →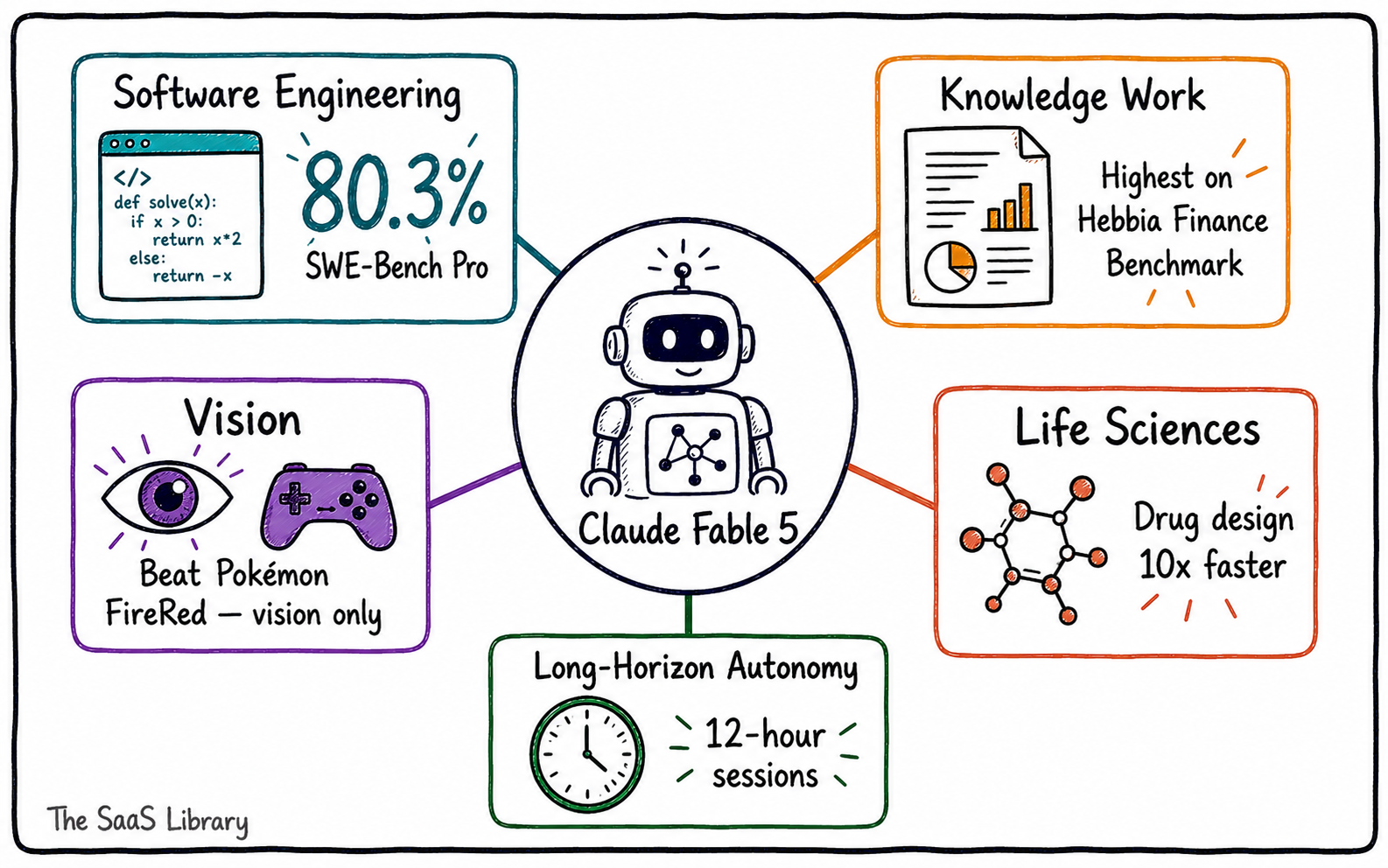
How does Claude Fable 5 compare to GPT-5.5 and Gemini 3.1 Pro?
Claude Fable 5 compares to GPT-5.5 and Gemini 3.1 Pro as the clear capability leader — but each model holds a defensible position that benchmark scores alone do not capture.
Three flagship models now define the frontier. Anthropic’s Claude Fable 5 shipped June 9, 2026. OpenAI’s GPT-5.5 shipped April 23, 2026. Google’s Gemini 3.1 Pro shipped February 19, 2026.
They were benchmarked at different times, on differently configured test harnesses. A one-to-three point difference between vendor-reported scores is directional, not exact — with one exception: the coding gap between Fable 5 and its nearest competitor is 21.7 points on SWE-Bench Pro (Anthropic, June 2026). That is not noise.
Benchmark comparison
| Benchmark | Claude Fable 5 | GPT-5.5 | Gemini 3.1 Pro | Source |
|---|---|---|---|---|
| SWE-Bench Pro | 80.3% ↑ | 58.6% | 54.2% | Anthropic, June 2026 |
| SWE-Bench Verified | 95.0% | — | — | Anthropic, June 2026 |
| FrontierCode (Diamond) | 29.3% | 5.7% | — | Cognition / Anthropic, June 2026 |
| HLE (with tools) | 64.5% | 52.2% | — | Anthropic, June 2026 |
| GPQA Diamond | 94.5% | 93.0% | leads | Anthropic, June 2026 |
| AA Intelligence Index | 64.9 (#1) | ~60 | ~57 | Artificial Analysis, June 2026 |
On the independent Artificial Analysis Intelligence Index, Fable 5 scores 64.9 — nearly five points ahead of any other lab’s best model. Andrej Karpathy, AI researcher and Anthropic pretraining team member, described it on launch day as “SOTA on everything by a margin” and “a major-version-bump-deserving step change forward” (Karpathy, X, June 9, 2026).
Pricing comparison
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Source |
|---|---|---|---|
| Claude Fable 5 | $10 | $50 ⚠️ | Anthropic, June 2026 |
| GPT-5.5 | $5 | $30 | OpenAI, April 2026 |
| Gemini 3.1 Pro | $2 | $12 ✓ | Google, February 2026 |
| Claude Opus 4.8 | $5 | $25 | Anthropic, 2026 |
Gemini 3.1 Pro is five times cheaper than Fable 5 on input tokens (Google, February 2026). GPT-5.5 is half the price on output (OpenAI, April 2026). For high-volume workloads where capable is genuinely good enough, the cost calculation changes entirely.
Where each model wins
Claude Fable 5 wins on raw capability, agentic coding, long-horizon autonomy, vision, and knowledge work. Cursor’s CEO Michael Truell described it as opening up “a class of long-horizon problems that were out of reach for earlier models” (Anthropic, June 2026).
GPT-5.5 wins on ecosystem depth and price-performance for terminal-centric coding. Teams already building on OpenAI infrastructure face switching costs that benchmark gaps do not automatically justify. For high-volume standard coding, it remains the sharper value at $5/$30 per million tokens (OpenAI, April 2026).
Gemini 3.1 Pro wins on cost and multimodal breadth. At $2 input per million tokens, it is the only model that makes frontier AI economically viable for organisations that cannot absorb Fable 5’s pricing (Google, February 2026). It leads on GPQA Diamond and holds the strongest native multimodal architecture of the three (BenchLM, June 2026).
Both Anthropic and OpenAI now gate cybersecurity and biology behind vetted access programs (Anthropic, June 2026). The safety posture has converged — which means the frontier has moved past raw capability into a new question: who is allowed to use it, and at what cost.
For a deeper look at how Claude and ChatGPT have historically compared, and for teams managing transitions, see our guide on Claude Opus 4.8 workflow migration.
Should you upgrade from Claude Opus 4.8 to Fable 5?
Claude Fable 5 beats Opus 4.8 by 10 to 20 points across Anthropic’s internal evaluations, according to head of product Dianne Na Penn (Fortune, June 2026) — and the published numbers bear that out: 80.3% vs 69.2% on SWE-Bench Pro, a gap of 11.1 points (Anthropic, June 2026). The cost of that gain is exactly double: Fable 5 is $10/$50 per million tokens against Opus 4.8’s $5/$25 (Anthropic, 2026).
For teams on long-horizon agentic workflows, large migrations, or tasks where Opus 4.8 currently requires multiple retries, the upgrade pays for itself the same way it did for Stripe — fewer correction turns absorb the price difference. For teams using Opus 4.8 for routine, high-volume, or simple tasks where it already performs well, doubling the per-token cost for an 11-point benchmark gain is a harder case to make, and migrating existing Opus workflows is worth doing selectively rather than wholesale. One practical note: until June 22, 2026, Fable 5 is included on subscription plans at no extra cost — making this the cheapest possible window to test whether the upgrade is worth it for your specific workload before the pricing cliff applies.
So far: what Fable 5 is, what it can do, and how it stacks up on benchmarks and price. Next: who this model is actually built for — and who the pricing leaves behind.

Who is Claude Fable 5 actually for — and who gets left behind?
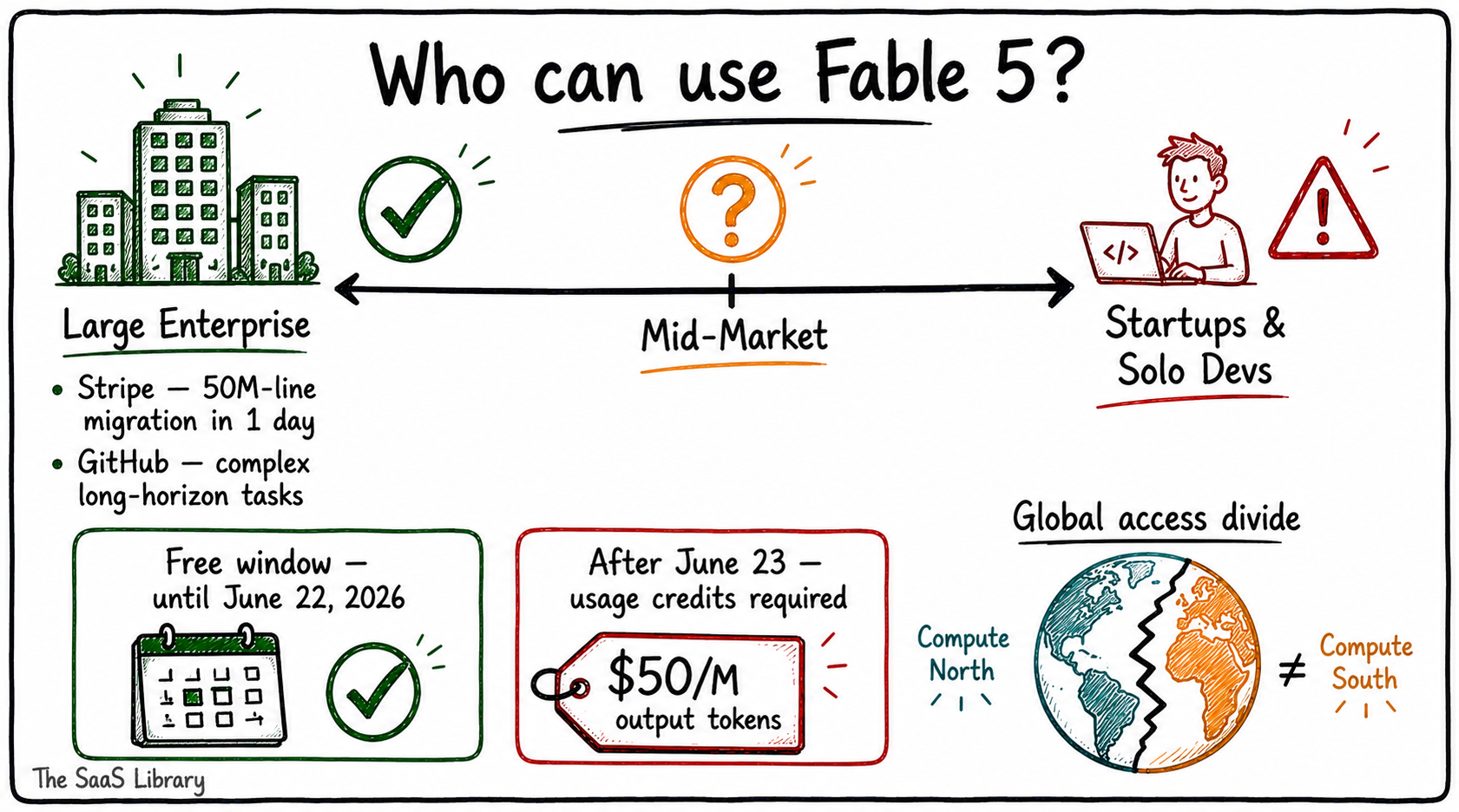
Claude Fable 5 is built for large engineering organisations, research institutions, and enterprise teams running complex, long-horizon workloads — and its pricing makes that audience explicit.
At $50 per million output tokens, Fable 5 costs double Anthropic’s previous flagship Opus 4.8, and five times more than Gemini 3.1 Pro on input (Anthropic, June 2026). For organisations like Stripe, the return on investment is unambiguous. For a solo developer or seed-stage startup, the cost calculation changes entirely — and estimating what agentic AI actually costs before you commit matters more than ever.
The enterprise case is clear
GitHub described Fable 5 as handling complex, long-horizon coding tasks with autonomy and reliability that exceeded previous benchmarks (Anthropic, June 2026). Equinox CTO Luke Anderson noted it delivers “more capable engineering in fewer turns than prior models” (Anthropic, June 2026).
When a model finishes in one pass what cheaper models need five attempts for, the per-token premium reverses into a net saving. This also connects to the gap between deploying AI agents and controlling them — a challenge 96% of companies are now navigating.
The startup and indie developer reality is more complicated
Reddit threads from the first 24 hours after launch are full of developers reporting dramatic quality improvements alongside sticker shock and refusals on edge cases (NerdsChalk, June 2026). Many describe Opus 4.8, GPT-5.5, and Gemini 3.1 Pro as already feeling “good enough” for their workflows — making Fable 5’s premium difficult to justify on marginal gains alone.
The subscription cliff
From launch through June 22, 2026, Fable 5 is included at no extra cost on Pro, Max, Team, and seat-based Enterprise plans (Anthropic, June 2026). On June 23, it moves to usage credits — token-based billing replacing subscription pricing in real time. Ethan Mollick flagged the problem on launch day: “The fact that Anthropic may take away subscription access to Fable in two weeks is weird and discourages investing in learning about the model. Only having paid access is limiting” (Mollick via Techmeme, June 2026).
The affordability divide is not theoretical
On the first day of launch, one user posted: “I’ve never felt the permanent underclass more than today” — after learning Fable 5 would not be part of standard subscription plans long-term (Techmeme, June 2026). That reaction signals something the benchmark tables do not: access to the best AI is already beginning to feel like a class distinction, not a product decision.
The global picture is sharper still. Only a small number of organisations can afford the compute required to develop frontier models (arXiv, 2025). Countries without affordable electricity, cutting-edge chips, or research universities are being asked to rent the future from those that have it (UNDP, January 2026). Fable 5’s $50 output pricing does not create this divide. It extends one that was already forming.
What have people already built with Claude Fable 5?
Claude Fable 5 has already been used to migrate production codebases, generate fully playable video games, build complex data visualisations, and accelerate scientific research — all within the first 48 hours of public availability.
These are not controlled demo results. They are real-world AI agent use cases in enterprise SaaS, reported by engineers, researchers, and developers who had early or launch-day access. The pattern is consistent: Fable 5 does not just complete tasks faster. It completes tasks that were previously out of reach entirely.
Stripe — enterprise codebase migration
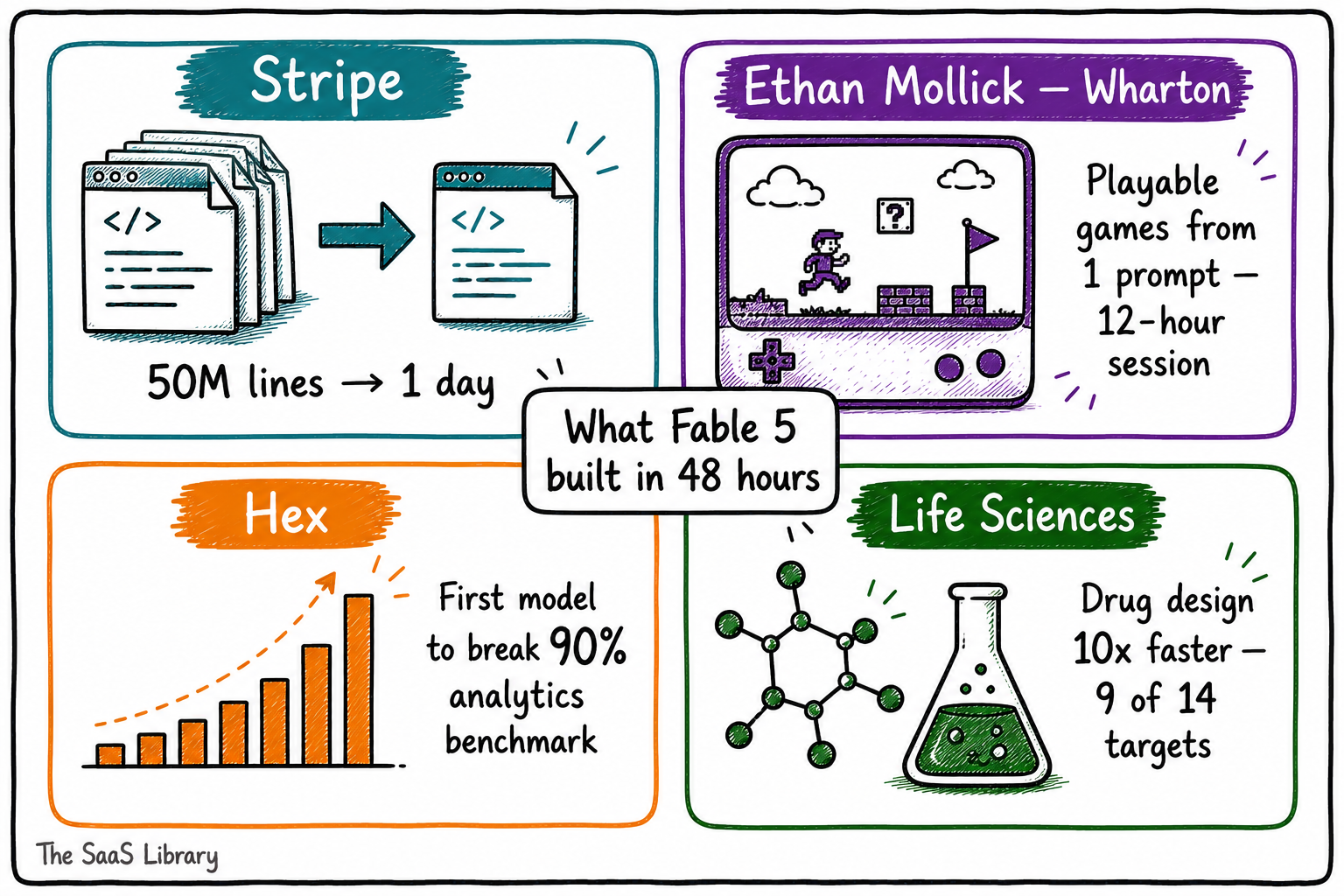
Stripe gave Fable 5 a 50-million-line Ruby codebase and asked it to perform a full migration. The model completed it in a single day — a task that would have required a whole engineering team more than two months by hand (Anthropic, June 2026). Not a benchmark. Not a demo. A production result on one of the most complex codebases in commercial software.
Hex — analytical benchmark breakthrough
Fable 5 became the first AI model to cross the 90% threshold on Hex’s core analytics benchmark — a 10-point jump over Opus 4.8 (Anthropic, June 2026). Hex’s AI Research Lead Izzy Miller described it as showing “strong judgment and attention to nuance” on the hardest questions in the benchmark.
Ethan Mollick — playable games from a single prompt
Ethan Mollick, AI researcher and associate professor at Wharton, used Claude Code to generate multiple fully playable video games from a single initial prompt — with Fable 5 executing multi-page specifications over sessions of up to 12 hours (Mollick, One Useful Thing, June 2026). The games included Snake, Strata, and Duino. His assessment: Fable 5 “outperformed basically every other public model I have used by a considerable margin.”
This connects directly to the shift in building functional tools from a single prompt — and what it means for how AI agents execute multi-step workflows autonomously.
Ethan Mollick — isochronic travel map of NYC
Using the same single-prompt workflow, Mollick generated a detailed isochronic map of New York City — a complex visualisation showing travel times between any two points across the city (Mollick, One Useful Thing, June 2026). A project that would previously have required a full development team was produced from one prompt in a single session.
Life sciences — drug design 10x faster
Using Mythos 5 — the unrestricted version sharing Fable 5’s underlying model — Anthropic’s protein design experts accelerated drug design by approximately ten times (Anthropic, June 2026). Nine of 14 protein targets yielded strong candidates currently under investigation for drug development.
Genomics — outperforming a Science paper
Using Mythos 5, Anthropic’s researchers assembled single-cell data for millions of cells spanning 138 animal species and trained a custom ML model that outperformed a recently published model in the journal Science — despite being 100 times smaller (Anthropic, June 2026).
The implication, as TechCrunch noted on launch day, is that “the automation frontier is not a fixed line. It is a moving wave” (TechCrunch, June 2026).
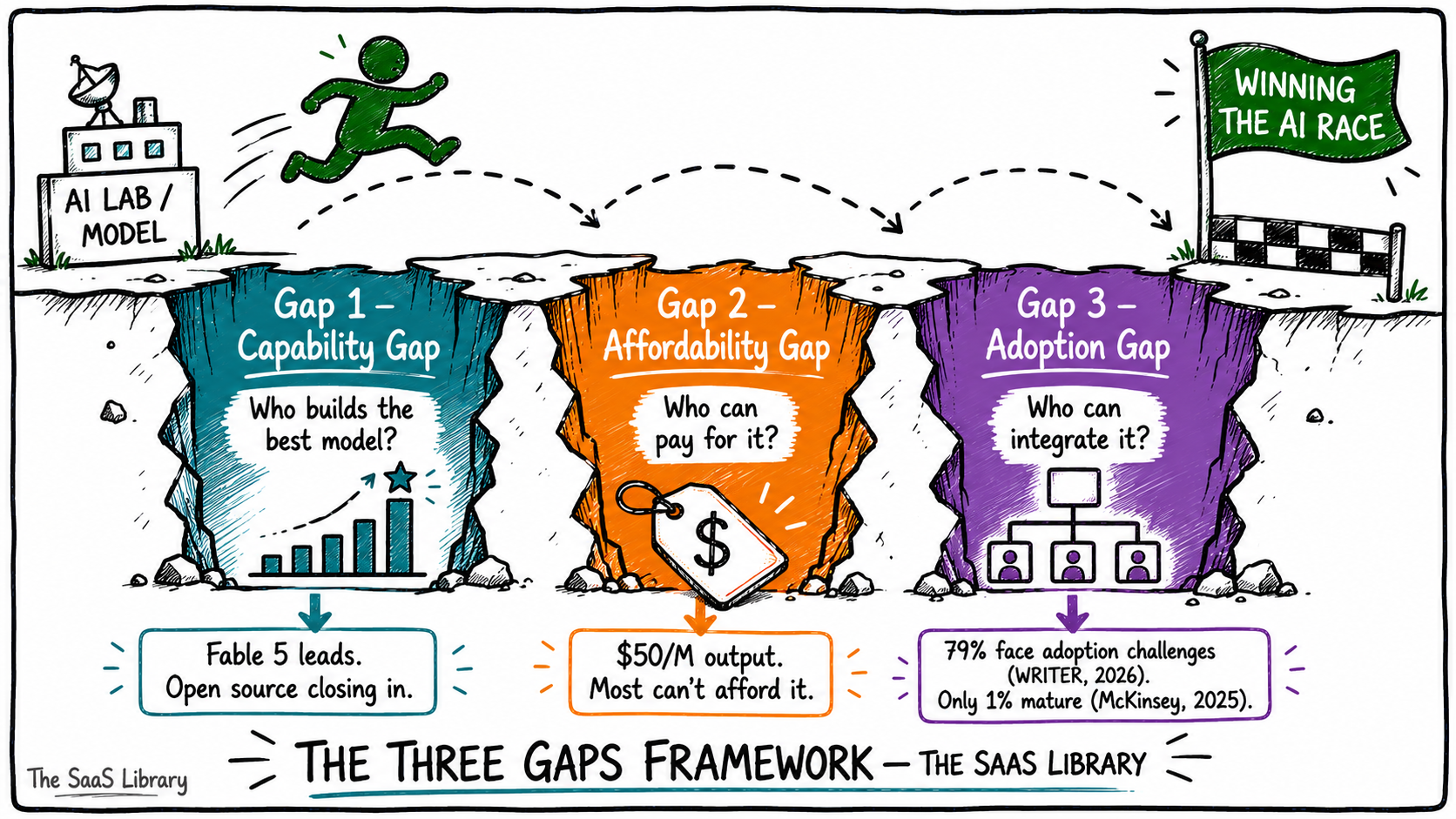
The Three Gaps — the framework the AI race forgot
The AI race in 2026 is being measured by one variable: capability. That is the wrong variable.
Every benchmark table published since Fable 5 launched ranks models by what they can do. None of them rank organisations by whether they can actually use what is being built. That gap between model capability and organisational reality is where the real competition is happening — and it is not a single gap. It is three.
The Three Gaps Framework identifies the three forces that determine who actually wins the AI race: the Capability Gap, the Affordability Gap, and the Adoption Gap. Closing one without the others does not win the race. It just changes which gap limits you first.
Gap 1: The Capability Gap
The Capability Gap is the difference in raw performance between frontier models — and it is the only gap the industry currently measures.
Fable 5 leads every major benchmark by a margin that is not noise. Its 21.7-point lead over GPT-5.5 on SWE-Bench Pro is larger than the entire gap between GPT-5.5 and Gemini 3.1 Pro (Anthropic, June 2026). On the independent Artificial Analysis Intelligence Index, Anthropic sits nearly five points ahead of any other lab (Artificial Analysis, June 2026).
But the Capability Gap has a defined expiry. The gap between frontier proprietary models and capable open-source alternatives is narrowing faster than most organisations realise (LLM Stats, June 2026).
Llama, Mistral, and Qwen now match or beat GPT-4 on several benchmarks. DeepSeek V4 Pro, released April 24, 2026, achieves near-frontier coding performance at $0.87 per million output tokens — approximately 57 times cheaper than Fable 5 on output alone (InfoWorld / DeepSeek, May 2026). The capability lead Fable 5 holds today is not a permanent structural advantage. It is a window.
Understanding how AI is reshaping search and content discovery is inseparable from understanding how quickly capability leads erode.
Gap 2: The Affordability Gap
The Affordability Gap is the distance between what the best AI costs and what most organisations can actually pay — and it is widening at exactly the moment capability is accelerating.
Fable 5’s $50 per million output tokens prices out the majority of the global market (Anthropic, June 2026). Countries without affordable electricity, cutting-edge chips, or research universities are being asked to rent the future from those that have it (UNDP, January 2026). The development of frontier models requires resources accessible only to elite institutions and large technology companies — a compute divide that widens as models advance (arXiv, 2025).
A well-funded enterprise engineering team and a three-person SaaS startup both have access to the same API endpoint. They do not have the same capacity to absorb $50 per million output tokens at production scale. The model is the same. The competitive reality is not.
The hidden costs of AI adoption most organisations overlook extend well beyond the token price.
Gap 3: The Adoption Gap
The Adoption Gap is the distance between an organisation having access to a capable AI model and actually integrating it into how work gets done — and it is the largest and least discussed of the three.
AI capability is advancing faster than organisational capability (IBM, June 2026). In 2026, 79% of organisations face challenges adopting AI despite high investment and near-universal deployment of AI agents (WRITER / Workplace Intelligence, May 2026). McKinsey found that only 1% of organisations consider their AI strategies mature (McKinsey, 2025).
Gartner predicts that by 2028, 33% of enterprise software applications will include agentic AI — up from less than 1% in 2024 (Gartner, June 2025). The question is not whether agentic AI will be embedded in enterprise software. The question is whether the organisations adopting it have the operational foundation to make it work.
Between February 5 and April 23, 2026, Anthropic, OpenAI, and Google collectively released seven frontier models in 78 days — a new state-of-the-art system approximately every 11 days (Job Security Meter, April 2026). The organisations winning the AI race are not the ones with access to the best model. They are the ones that have built the internal systems to absorb each new generation before the next one arrives.
The model you cannot integrate is the model you do not have — regardless of what it scores on a benchmark.
Governance readiness is one of the biggest structural barriers to adoption. See our full analysis of AI governance readiness in enterprise SaaS. For organisations optimising how they get discovered by AI systems, optimising for AI-generated answers and understanding how LLMs discover and cite content are increasingly critical.
The framework applied
The Three Gaps reframes the question the AI race is actually asking. It is not: who built the most capable model? Anthropic answers that today with Fable 5. It is: who can close all three gaps simultaneously — building capability, making it affordable at scale, and integrating it faster than the release cycle moves?
No lab has answered all three. No organisation has either. That is what makes the next phase of the AI race genuinely open — and genuinely consequential.
Closing one gap without the others does not win the race. The organisations that will define what AI looks like in 2027 are the ones closing all three simultaneously — building capability, making it affordable, and integrating it faster than the release cycle moves. See how the build vs buy decision shapes your gap strategy.
Only 1% of organisations consider their AI strategies mature — meaning 99% face the Adoption Gap in some form. (McKinsey, 2025)
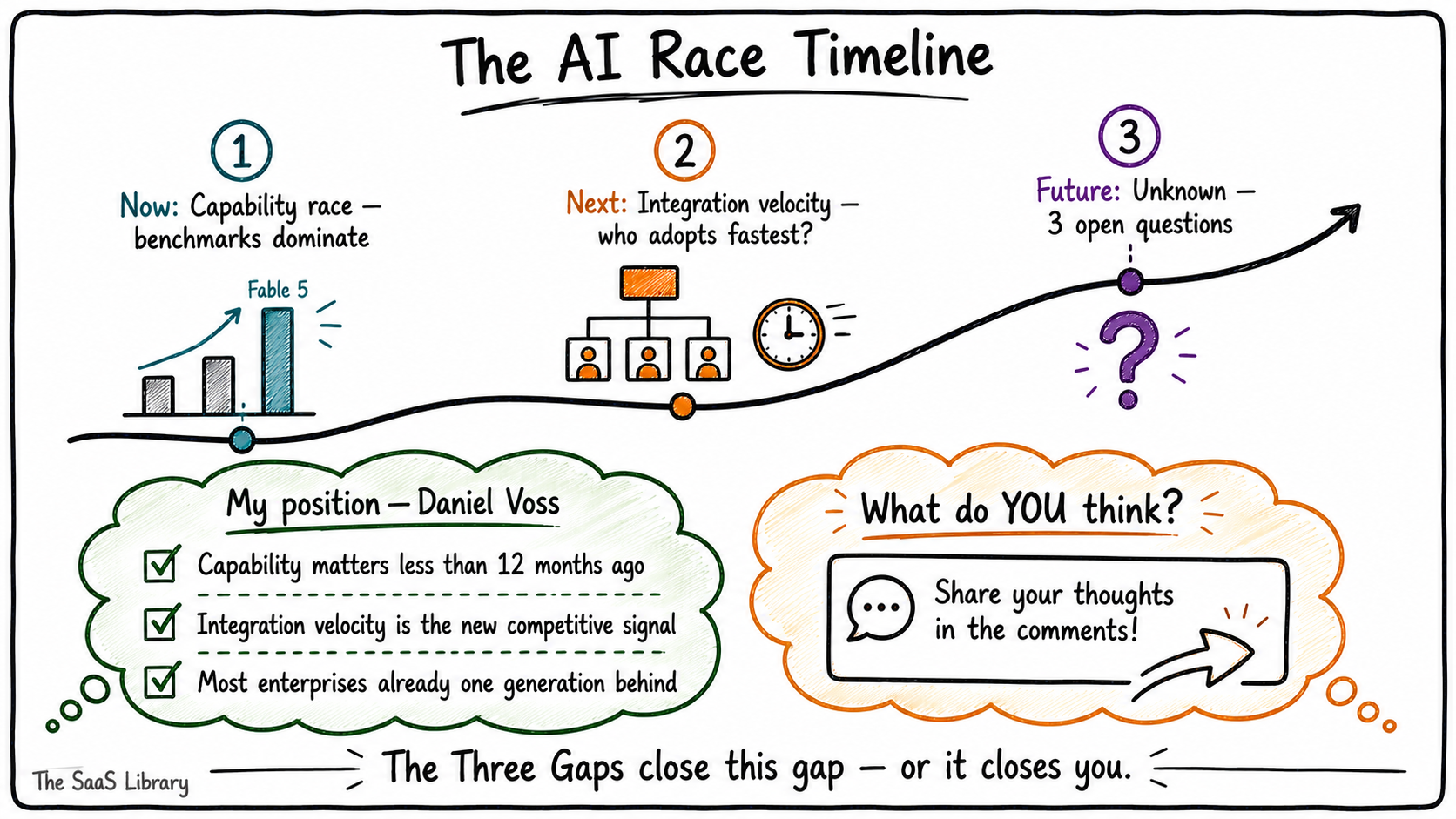
What happens next — and what I think, honestly
The future of the AI race looks less like a sprint between labs and more like a stress test of who can absorb what gets built.
That is my read. Not a prediction — a position, based on what the evidence shows and where it points. I could be wrong. The honest thing is to say so, and then tell you what I actually think.
On Question 1: When does “better AI” stop mattering?
My position is that capability already matters less than it did twelve months ago — not because the capability gap has closed, but because it has become less actionable.
Fable 5 leads every benchmark by a margin that is not noise. But McKinsey found that only 1% of organisations consider their AI strategies mature (McKinsey, 2025). A model that is objectively the best in the world delivers zero competitive advantage to the 99% of organisations that cannot integrate it effectively.
The capability ceiling keeps rising. The organisational floor is rising far more slowly. At some point — and I think that point is closer than most coverage suggests — the marginal gain from the next benchmark improvement matters less than the ability to deploy what already exists.
What replaces raw capability as the primary competitive signal? My read is that it is integration velocity — the speed at which an organisation can move from model release to productive deployment. The organisations building that muscle now hold a compounding advantage that transfers across providers and model generations. The model you use matters. How fast you can use it matters more.
This is why chasing AI trends destroys thought leadership — and why building AI agent workflows now is more valuable than waiting for the next frontier model.
On Question 2: Are enterprises permanently one generation behind?
My position is that most enterprises already are — and the release cadence is not slowing down.
Seven frontier models in 78 days between February and April 2026 (Job Security Meter, April 2026). Fable 5 on June 9. Anthropic’s own announcement signals that more capable models are arriving in the coming months (Anthropic, June 2026).
The organisations that are winning are not the ones chasing each release. They are the ones that have stopped treating model selection as a strategy and started treating operational readiness as one.
The competitive advantage in the AI race is not which model you are running. It is whether your organisation can run any model well.
The Citadel Securities analysis puts it plainly: technological diffusion has historically followed an S-curve — early adoption is slow and expensive, growth accelerates as costs fall, and eventually saturation sets in (Citadel Securities, April 2026). The evidence suggests we are still in the acceleration phase. But organisations treating this phase as permanent are the ones most exposed when it ends.
For a wider view of what is actually changing in B2B SaaS in 2026, this acceleration is the central thread.
What I do not know
I do not know whether open-source models will close the capability gap fast enough to commoditise frontier AI within the next 18 months. I do not know whether pricing will compress to the point where the Affordability Gap becomes a historical footnote or hardens into a permanent structural divide.
I do not know whether the adoption problem is solvable at the pace the release cycle demands — or whether it produces a permanent class of organisations that are always one generation behind, no matter how much they invest. Those are not rhetorical questions. They are the open problems that will define the next chapter of this race.
Now I want to know what you think
The Three Gaps Framework is my attempt to reframe the question the AI race is asking. But frameworks are tools, not verdicts. The question I am genuinely sitting with — and I suspect you are too — is this:
If capability is no longer the primary competitive variable, what is? And is there a version of this race that more organisations actually get to win?
Leave your answer in the comments. This is one of those questions where the conversation after the article matters more than the article itself.
Frequently Asked Questions
What is Claude Fable 5?
Claude Fable 5 is Anthropic’s first Mythos-class AI model released for general use, launched June 9, 2026. It shares the same underlying architecture as Claude Mythos 5, with safety classifiers added for cybersecurity, biology, chemistry, and model distillation. It leads all major coding, reasoning, and knowledge benchmarks and is accessible via the Claude API, Claude.ai, Claude Code, and third-party platforms including GitHub Copilot, Amazon Bedrock, and Google Cloud Vertex AI.
What is the difference between Claude Fable 5 and Claude Mythos 5?
Claude Fable 5 and Claude Mythos 5 share identical underlying model weights. The difference is safeguards. Fable 5 includes safety classifiers that detect queries related to cybersecurity, biology, chemistry, and model distillation, and route those queries to Claude Opus 4.8 instead. Mythos 5 has those safeguards lifted in some areas and is available only to vetted Project Glasswing partners — cyberdefenders, infrastructure providers, and select biology researchers.
How does Claude Fable 5 compare to GPT-5.5?
Claude Fable 5 leads GPT-5.5 on every major coding and reasoning benchmark. On SWE-Bench Pro, Fable 5 scores 80.3% against GPT-5.5’s 58.6% — a 21.7-point gap larger than the gap between GPT-5.5 and Gemini 3.1 Pro. On the independent Artificial Analysis Intelligence Index, Fable 5 scores 64.9 against GPT-5.5’s approximately 60. GPT-5.5 holds an advantage on price at $5/$30 per million tokens versus Fable 5’s $10/$50, and on ecosystem depth for teams already building on OpenAI infrastructure.
How much does Claude Fable 5 cost?
Claude Fable 5 is priced at $10 per million input tokens and $50 per million output tokens on the Anthropic API. Batch pricing is $5 per million input tokens and $25 per million output tokens. Prompt caching reduces input costs by approximately 90% on cached content. From launch through June 22, 2026, Fable 5 is included at no extra cost on Pro, Max, Team, and seat-based Enterprise plans. After June 23, usage requires credits on those plans.
Is Claude Fable 5 available on free plans?
Claude Fable 5 is not available on free plans. From launch through June 22, 2026, it is included at no extra cost on paid subscription plans — Pro, Max, Team, and seat-based Enterprise. After June 23, 2026, usage on subscription plans requires usage credits. It is fully available from launch on the Claude API and consumption-based Enterprise plans.
What is Claude Fable 5 best used for?
Claude Fable 5 is best used for large-scale software engineering, complex codebase migrations, long-horizon agentic tasks, senior-level knowledge work, vision-based tasks including document analysis and UI reconstruction, and scientific research workflows. The longer and more complex the task, the larger its performance advantage. It is less cost-effective for simple, high-volume, or repetitive tasks where Gemini 3.1 Pro or Claude Opus 4.8 offer comparable results at significantly lower cost.
Why does Claude Fable 5 sometimes fall back to Opus 4.8?
Claude Fable 5 falls back to Opus 4.8 when its safety classifiers detect a query related to cybersecurity, biology and chemistry, or frontier AI research and distillation. This is by design — Mythos-class models have capabilities in these areas that Anthropic determined pose significant risk of misuse without safeguards. The fallback triggers in less than 5% of sessions on average. As of June 2026, all four classifier categories route visibly to Opus 4.8 with a stated reason. The response from Opus 4.8 is still a high-quality answer — not a refusal.
Should I upgrade from Claude Opus 4.8 to Fable 5?
Upgrade if you run long-horizon agentic workflows, large codebase migrations, or tasks where Opus 4.8 currently needs multiple retries — Fable 5 scores 80.3% vs Opus 4.8’s 69.2% on SWE-Bench Pro, an 11.1-point gain, and fewer correction turns can absorb its doubled price ($10/$50 vs $5/$25 per million tokens). For routine, high-volume, or simple tasks where Opus 4.8 already performs well, the upgrade is harder to justify. Fable 5 is free on subscription plans through June 22, 2026 — the cheapest window to test it on your specific workload before deciding.
Why did Anthropic apologize for Claude Fable 5’s hidden guardrails?
At launch, Fable 5’s frontier-AI-research classifier could silently weaken responses to queries related to large-scale model training without telling the user — unlike the cybersecurity and biology classifiers, which visibly routed to Opus 4.8. AI researchers discovered this in the model’s system card within hours and called it anti-competitive and non-transparent. Anthropic apologized to Fortune and Wired, calling it “the wrong tradeoff,” and within roughly 24 hours made the frontier-research fallback visible, matching the existing cybersecurity and biology pattern.
What is the Three Gaps Framework?
The Three Gaps Framework is a model for understanding what actually determines who wins the AI race. It identifies three gaps that organisations must close simultaneously: the Capability Gap — the difference in raw performance between frontier models; the Affordability Gap — the distance between what the best AI costs and what most organisations can pay; and the Adoption Gap — the distance between having access to a capable model and integrating it effectively into how work gets done. Closing one gap without the others does not produce competitive advantage.
Will AI capability keep improving at this pace?
AI capability has improved at roughly a constant rate on Anthropic’s internal Effective Compute Index, with Fable 5 continuing the trend established by previous model generations. Between February and April 2026 alone, the world’s three leading AI labs released seven frontier models in 78 days. Whether this pace is sustainable depends on compute availability, algorithmic progress, and the economics of frontier model development. No lab has publicly indicated a slowdown. Whether the pace of organisational adoption can match it is a separate and more uncertain question.
Can small businesses afford Claude Fable 5?
Small businesses can access Claude Fable 5 during the free window — through June 22, 2026 — on paid subscription plans at no extra cost. After that, sustained use requires usage credits, and at $50 per million output tokens, production-scale use cases become expensive quickly. For most small businesses, Claude Opus 4.8 at $5/$25 per million tokens or Gemini 3.1 Pro at $2/$12 per million tokens will deliver capable results at a fraction of the cost. Fable 5 makes economic sense for small businesses only on tasks where its reliability and long-horizon capability demonstrably reduce retries, correction turns, or human review time.
Conclusion
Claude Fable 5 is the most capable AI model ever made publicly available. The benchmarks are not close, the real-world results are not theoretical, and the release marks a genuine line in the AI race — not another incremental step.
But the Three Gaps Framework exists because capability alone has never been enough. The organisations that will define what AI looks like in 2027 are not the ones chasing the highest benchmark score. They are the ones closing all three gaps — capability, affordability, and adoption — simultaneously.
That is my read. I could be wrong. Subscribe to The SaaS Library for analysis that goes beyond the benchmark tables — and tell us in the comments: what do you think the real competitive variable in the AI race turns out to be?
- Anthropic — Claude Fable 5 and Claude Mythos 5 announcement, June 9, 2026
- Anthropic — Project Glasswing, April 2026
- Anthropic — Detecting and Preventing Distillation Attacks, 2026
- Fortune — Anthropic accused of “secret sabotage” over Claude Fable 5, June 2026
- Dataconomy — Anthropic apologizes for hidden Fable throttling, June 2026
- Let’s Data Science — Anthropic reverses Claude Fable 5 secret sabotage rule, June 2026
- Artificial Analysis — Claude Fable 5 Intelligence Index, June 2026
- Ethan Mollick — One Useful Thing, June 2026
- OpenAI — API Pricing, April 2026
- Google — Gemini API Pricing, February 2026
- BenchLM — Gemini 3.1 Pro vs GPT-5.5 comparison, June 2026
- NerdsChalk — Claude Fable 5 vs the World, June 2026
- Techmeme — Claude Fable 5 launch coverage, June 2026
- UNDP — The Next Great Divergence, January 2026
- arXiv — The Hidden Costs of AI: Inequality in Compute Access, 2025
- WRITER / Workplace Intelligence — 2026 Enterprise AI Adoption Survey, May 2026
- IBM — AI Adoption Challenges 2026
- McKinsey — State of AI 2025
- Gartner — Agentic AI Enterprise Predictions, June 2025
- Job Security Meter — Frontier AI Model Releases 2026, April 2026
- Citadel Securities — 2026 Global Intelligence Crisis, April 2026
- TechCrunch — Fable 5 video games article, June 2026
- Andrej Karpathy — X/@karpathy, June 9, 2026
- InfoWorld — DeepSeek V4 Pro permanent pricing, May 2026





