Most teams budget for agentic AI the same way they budget for a SaaS subscription — pick a model, estimate the tokens, multiply by volume. That math works for a chatbot. It breaks completely for an agent.
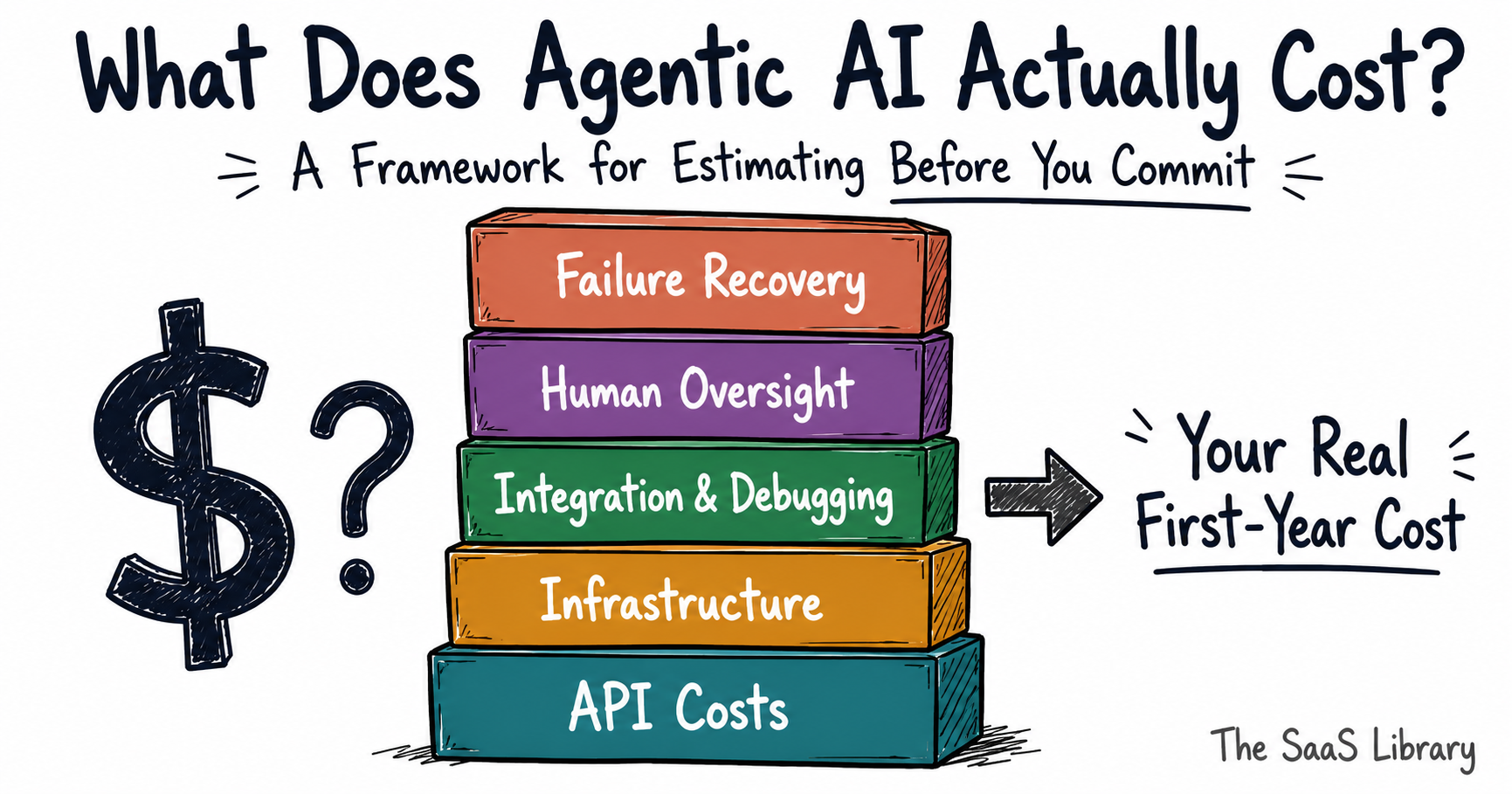
Most teams budget for agentic AI the same way they budget for a SaaS subscription — pick a model, estimate the tokens, multiply by volume. That math works for a chatbot. It doesn’t work for an agent. The real cost has five layers, and most pre-commitment budgets only price two of them. This article gives you a framework to estimate all five before a single dollar is spent.
AI Agents cost anywhere from $15,000 for a focused single-task agent to $400,000+ for enterprise multi-agent systems — but your first-year total cost of ownership typically runs 40–80% above your build estimate once you add infrastructure, integration, oversight, and failure recovery. This framework helps you price all five layers before you commit.
Why Does Agentic AI Cost More Than You Think (And Why That’s Not the Vendor’s Fault)?
The pricing page isn’t lying to you. The token rates are real. The problem is that token rates are the least of your cost concerns once an agent hits production.
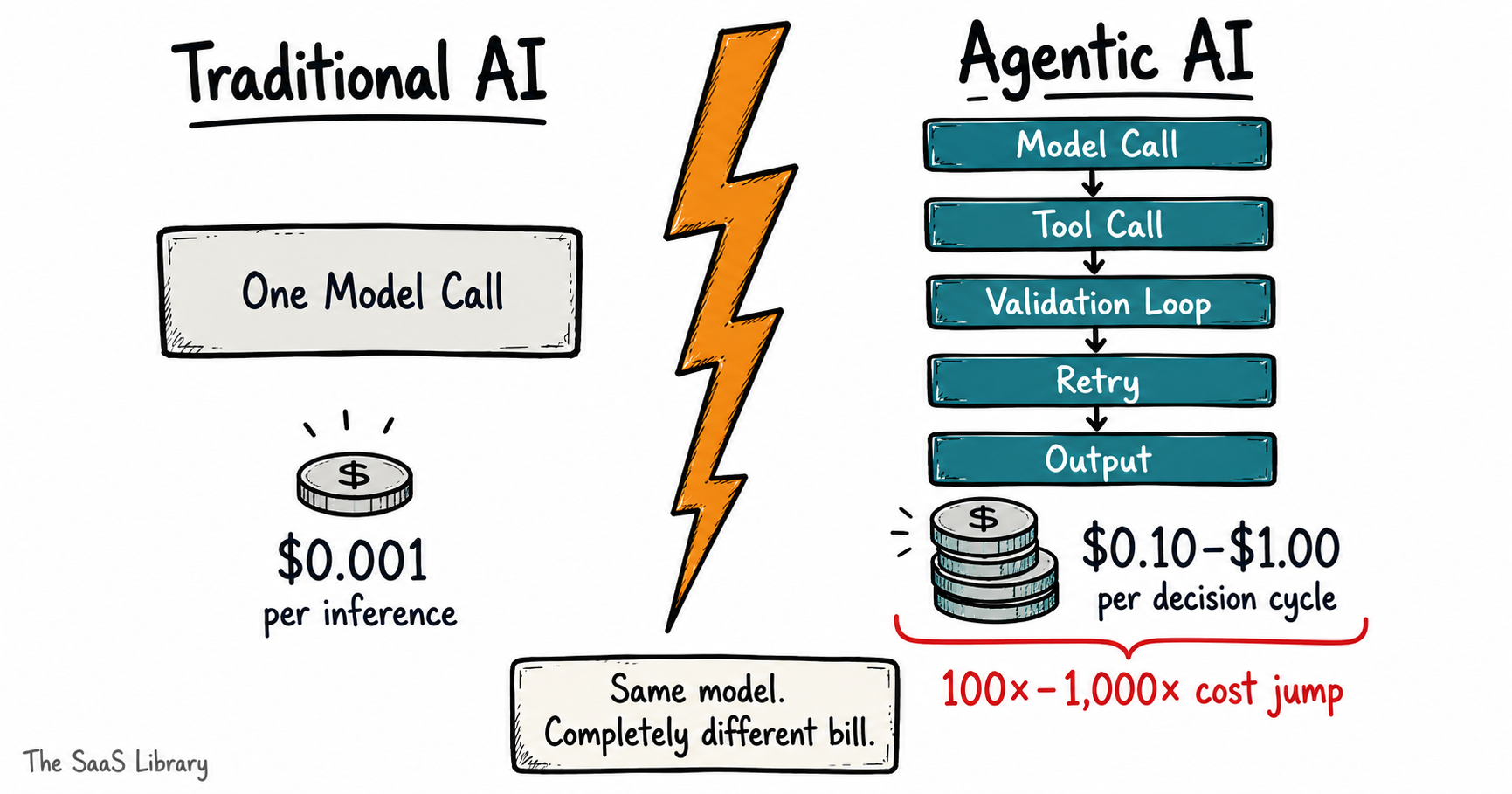
Here’s why. Traditional AI — a single-turn completion, a chatbot response, a summarisation task — costs roughly $0.001 per inference. Agentic AI, where a system plans multi-step actions, calls external tools, validates its own outputs, and loops back when something fails, runs $0.10 to $1.00 per complex decision cycle. That’s not a rounding error. That’s a 100× to 1,000× jump in per-unit cost before you’ve factored in a single line of infrastructure spend.
The reason isn’t vendor greed. It’s architectural reality. A single agentic workflow can involve multiple model calls, data retrieval from a vector database, tool-call execution across external APIs, validation loops, and downstream integrations — all within one user-facing interaction. Each of those steps consumes compute. Each retry compounds it. Each integration adds surface area for failure, which adds cost for recovery.
The cost model of software has shifted from fixed infrastructure to variable intelligence. You’re no longer paying for servers that sit idle at night. You’re paying for reasoning — and reasoning bills arrive in proportion to how much thinking your agent does, not how many users you have.
That shift demands a different estimation approach. Not “what does the model cost per token?” but “what does this agent cost per decision?” — and then multiplied across every decision it makes in a month. Gartner projects agentic AI software spending will reach $201.9 billion in 2026, a 141% increase year-over-year — and only 21% of companies running AI agents can actually control them. The cost gap and the control gap are the same problem viewed from different angles.
The framework in this article — the AGENT Cost Stack — maps five layers that together determine what you’ll actually spend. Layer one is the only one most budgets include. The other four are where projects quietly run out of runway.
What Does Layer 1 — Model API Costs — Actually Include?
Start here, but don’t stop here. Model API costs are the most visible line item in any agentic AI budget — and the easiest to underestimate, not because the pricing is hidden, but because agentic workflows consume tokens in ways that single-turn completions don’t.
A standard chatbot exchange might use 500–1,000 tokens. An agentic workflow handling a five-tool task — retrieving context, calling an API, validating the output, looping on failure, summarising the result — can consume 10,000 to 50,000 tokens per completed action. Same model. Completely different bill. If you’re evaluating Claude Sonnet 4.6 vs GPT-5 for your agent stack, model capability is only half the decision — per-workflow token consumption is the other half.
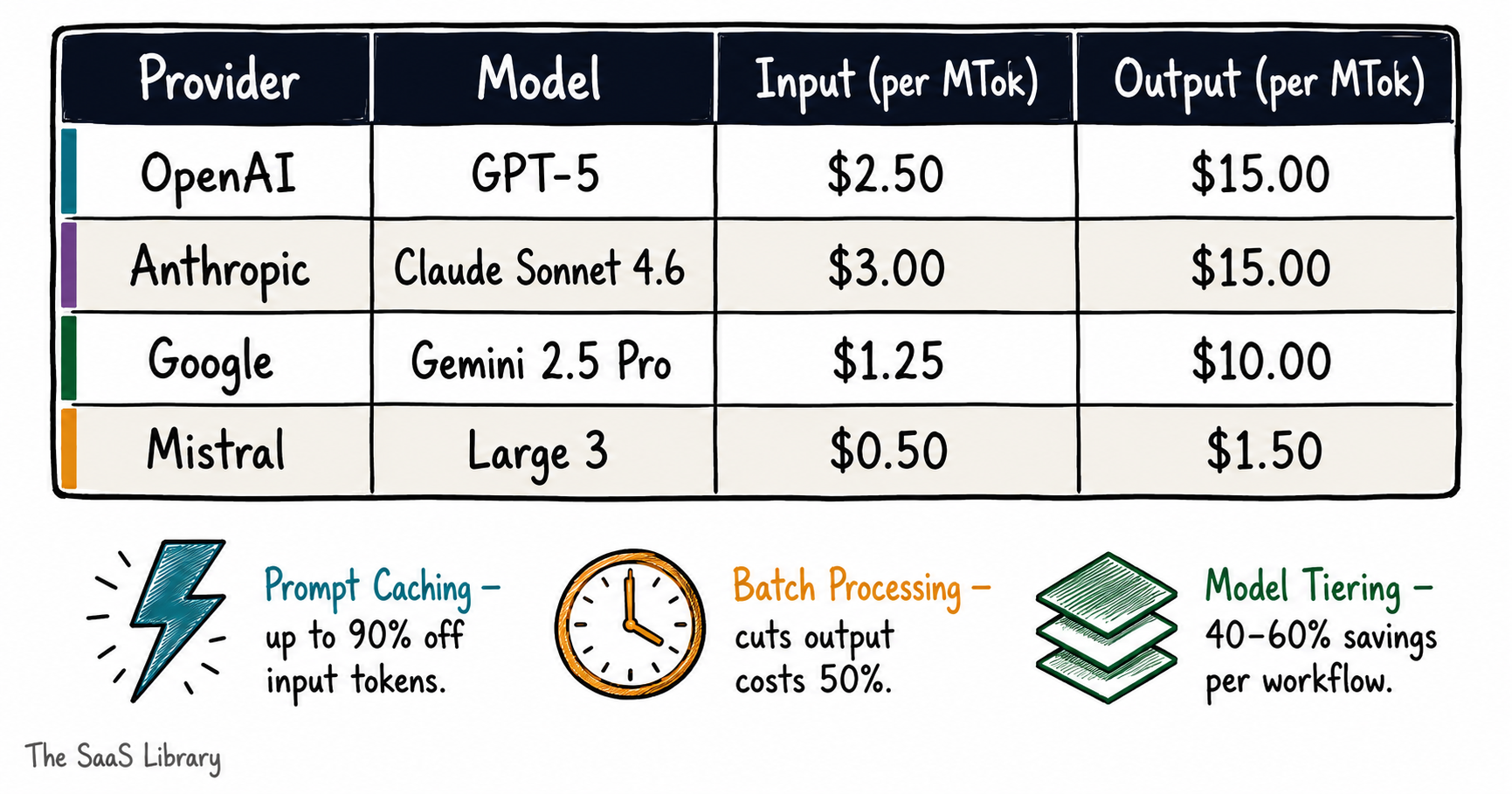
Here’s what the three major providers charge at standard rates in 2026, plus Mistral as the price-performance alternative for high-volume pipelines:
| Provider | Model | Input (per MTok) | Output (per MTok) | Best For |
|---|---|---|---|---|
| OpenAI | GPT-5 | $2.50 | $15.00 | Complex reasoning, deep tool use |
| Anthropic | Claude Sonnet 4.6 | $3.00 | $15.00 | Coding, large codebase analysis |
| Gemini 2.5 Pro | $1.25 | $10.00 | Long-context research, video/audio | |
| Mistral | Large 3 | $0.50 | $1.50 | High-volume pipelines, tight margins |
The 100× spread between the cheapest capable model and the most expensive flagship output tier means model selection is a cost decision as much as a capability decision. Three levers reduce your API spend before you touch anything else.
Prompt Caching
Both Anthropic and OpenAI now offer approximately 90% off cached input tokens. For agents that repeatedly load the same system prompt, knowledge base, or tool schema at the start of every session, caching alone can cut input costs by half or more on cache-heavy workloads.
Batch Processing
Anthropic’s batch API drops Claude Opus 4.7 to $2.50/$12.50 per MTok — matching GPT-5’s standard input rate. If your agent runs non-time-sensitive tasks, batch is an immediate cost lever with no architectural changes required. Teams already running Claude workflows should check how Opus 4.7 pricing differs from prior versions before assuming their cost baseline holds.
Model Tiering
You don’t need a flagship model for every step in an agentic pipeline. Use a lighter, cheaper model — Gemini Flash or Mistral Small at $0.06/$0.18 per MTok — for routing, classification, and validation tasks. Reserve the flagship for the reasoning-heavy steps that actually require it. This alone can reduce per-workflow API spend by 40–60%.
Already past the research phase and deciding whether to build custom or buy a platform solution?
Read the Build vs. Buy Breakdown →Why Is Layer 2 — Infrastructure and Orchestration — the Budget Black Hole?
If Layer 1 is the cost you see coming, Layer 2 is the one that doubles your bill without warning.
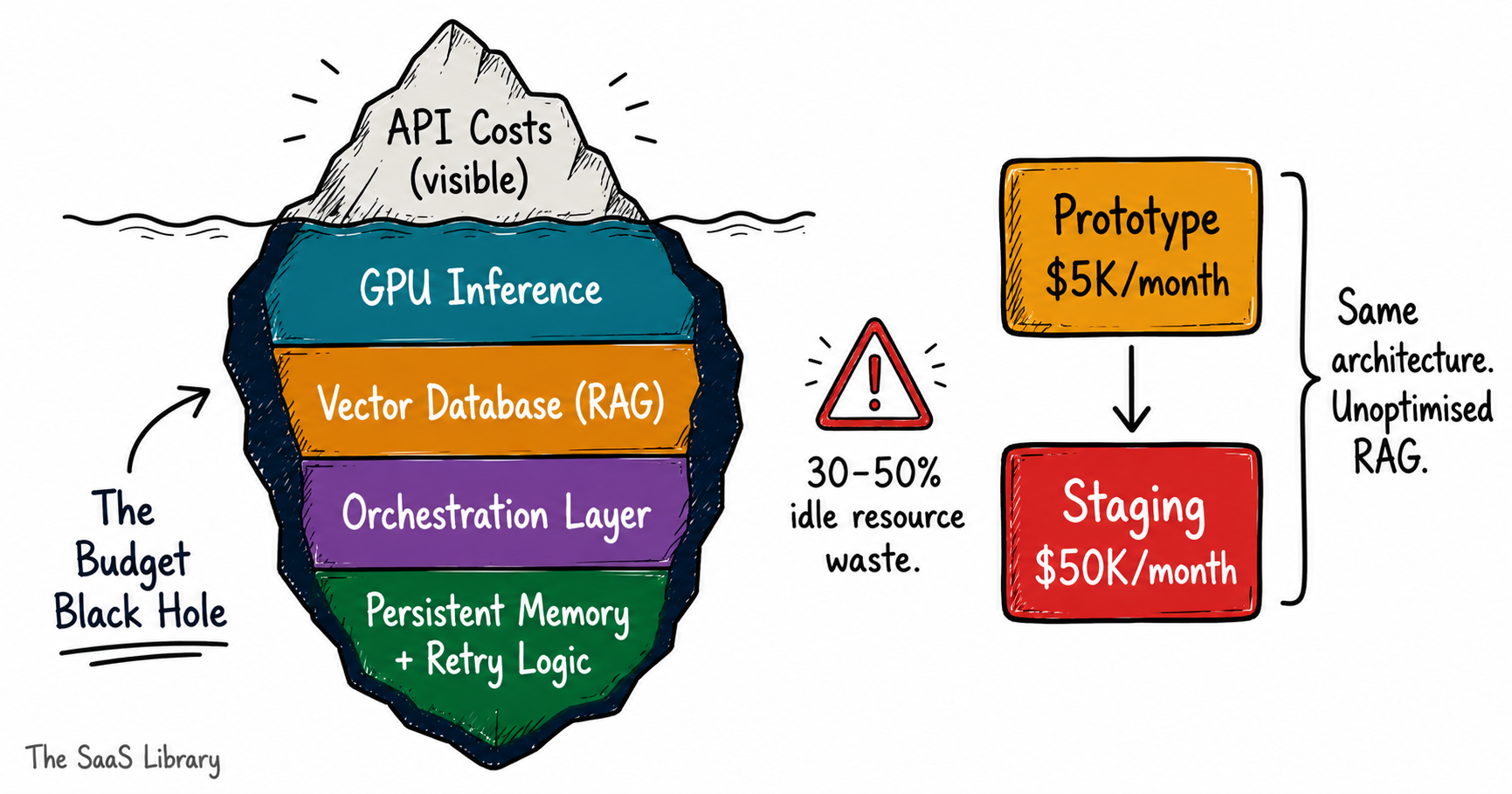
Infrastructure for agentic AI isn’t the same as infrastructure for a web app. You’re not provisioning servers to serve static requests. You’re provisioning a system that needs GPUs for inference, a vector database for retrieval-augmented generation, an AI workflow orchestration layer to manage multi-agent coordination, persistent memory storage across sessions, and retry logic for every tool call that fails. Each of those components carries its own cost curve — and they compound.
Cloud provider data puts idle resource waste and over-provisioning at 30–50% of total infrastructure spend for agentic AI deployments. That’s not inefficiency unique to bad teams. It’s the result of provisioning for peak load during development, then never right-sizing for production. Over-provisioning is especially common when teams test automation tools without production-scale benchmarks in place from day one.
A mid-sized e-commerce firm building an agentic supply chain optimizer saw infrastructure costs jump from $5,000/month during prototyping to $50,000/month in staging — driven entirely by unoptimized RAG queries fetching ten times more context than each task needed. The model costs hadn’t changed. The orchestration layer had.
There’s a second infrastructure cost that almost no pre-commitment budget accounts for: context window thrashing. When an agent’s context window fills up — due to long conversation histories, tool-call failures requiring rollback, or memory consolidation pauses — the session effectively resets. Benchmarks from Hugging Face’s AgentEval show that a typical customer support agent handling five-tool workflows incurs 2.3 session resets per hour due to context overflow. On Anthropic’s harness pricing, that turns a nominal $0.08 per session-hour into an effective $0.18 per session-hour — more than double, with no change in the work the agent is doing.
The pattern repeats almost identically across every mid-market deployment I’ve tracked: the prototype looks affordable, the staging environment breaks the budget, and the culprit is always the same — RAG queries fetching ten times more context than the task needs. Right-sizing retrieval isn’t an optimisation exercise. It’s the first infrastructure decision you make.
Right-Size Your RAG Retrieval
Fetching the minimum context needed per task — not the maximum available — is the single highest-leverage infrastructure cost control. Dynamic retrieval budgets that cap context per query prevent the compounding cost of over-fetched embeddings.
Auto-Scale Compute
Kubernetes-based orchestration with workload-triggered scaling can cut idle GPU costs by 20–40%. The goal is compute that tracks actual agent activity, not compute provisioned against worst-case concurrency.
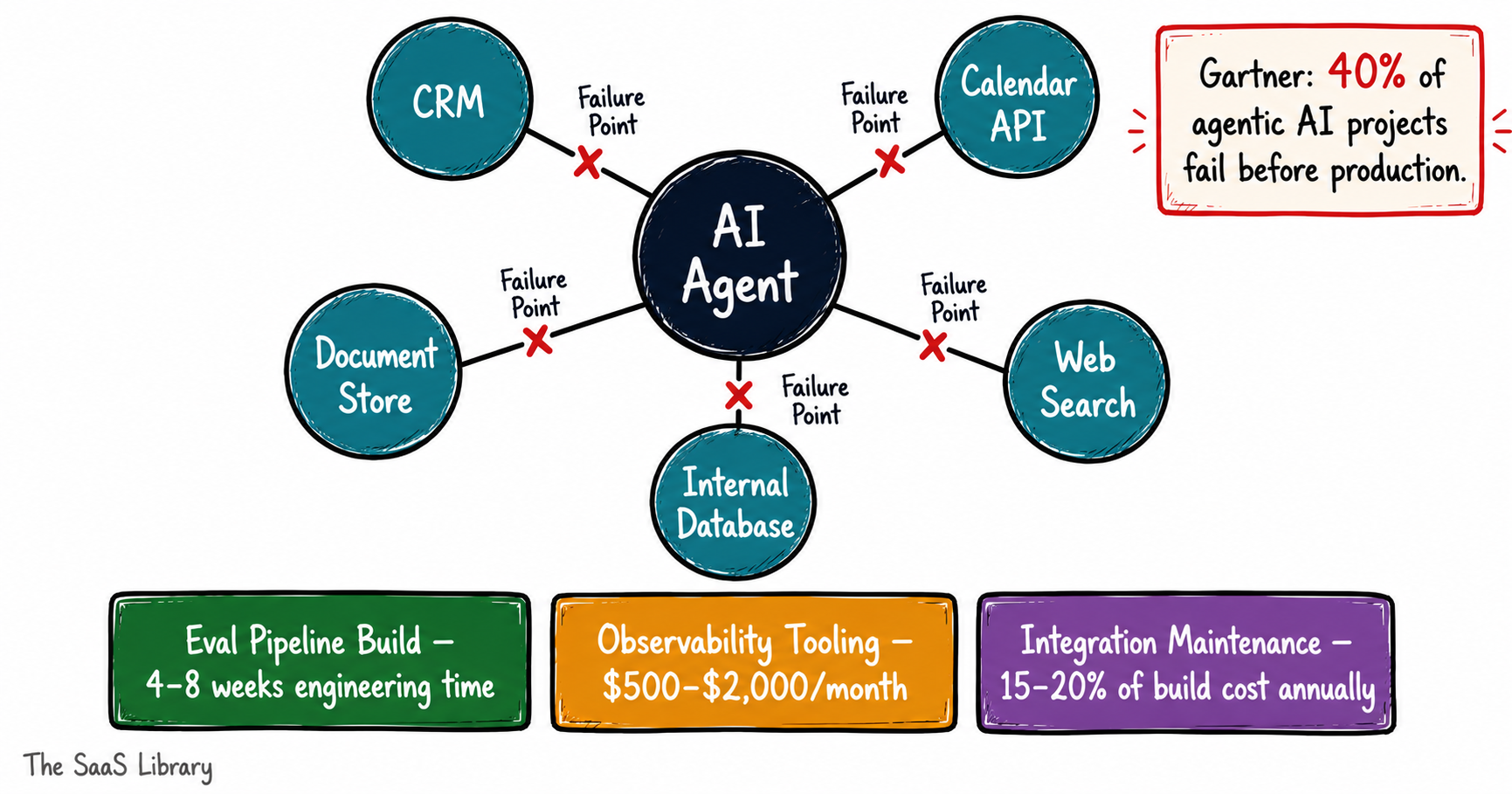
What Does Layer 3 — Integration, Evaluation, and Debugging — Actually Cost?
This is the layer that doesn’t appear on any vendor pricing page — and the one most likely to blow your timeline before it blows your budget.
Every tool your agent calls is an integration. Every integration needs to be built, tested, and maintained. A five-tool agentic workflow isn’t five times the complexity of a one-tool workflow — it’s closer to twenty-five, because each tool interaction creates failure surfaces that compound across the pipeline. Understanding how to build an AI agent step by step clarifies the full integration scope before costs compound. A practical example: an AI lead scoring system for B2B SaaS maps exactly the multi-tool complexity that drives debugging overhead in production.
Before any of that reaches production, you need an evaluation pipeline. You can’t ship an agent the way you ship a deterministic web feature — there’s no unit test that confirms an autonomous system will behave correctly across the full distribution of real inputs. Building that infrastructure is a project in itself, typically adding two to six weeks to any serious deployment timeline — and ongoing cost to every subsequent update.
Gartner projects that over 40% of agentic AI projects will fail to reach production by 2027. The capability is real. The evaluation and debugging infrastructure required to make it production-safe is where projects quietly stall.
Debugging compounds the problem. Traditional software fails with stack traces. Agents fail with wrong answers, partial completions, and silent loops. Isolating why an agent made a specific decision across a multi-step workflow requires purpose-built observability tooling that most teams don’t price into their initial build.
Eval Pipeline Build
Treat it as a first-class engineering workstream, not a QA afterthought. Budget four to eight weeks of engineering time for an agent handling more than three tools.
Observability Tooling
Platforms like Galileo, LangSmith, and Weights & Biases now offer agent-specific tracing. Budget $500–$2,000 per month depending on interaction volume. This is not optional for production deployments — it’s the difference between debugging in hours and debugging in days.
Integration Maintenance
External APIs change. Rate limits shift. Authentication tokens expire. Every live integration is an ongoing maintenance cost. Budget 15–20% of initial integration build time as annual upkeep per tool connected.
So far you’ve seen what model APIs, infrastructure, and integration actually cost. The next two layers — oversight and failure recovery — are where most projects run out of budget, and out of time.
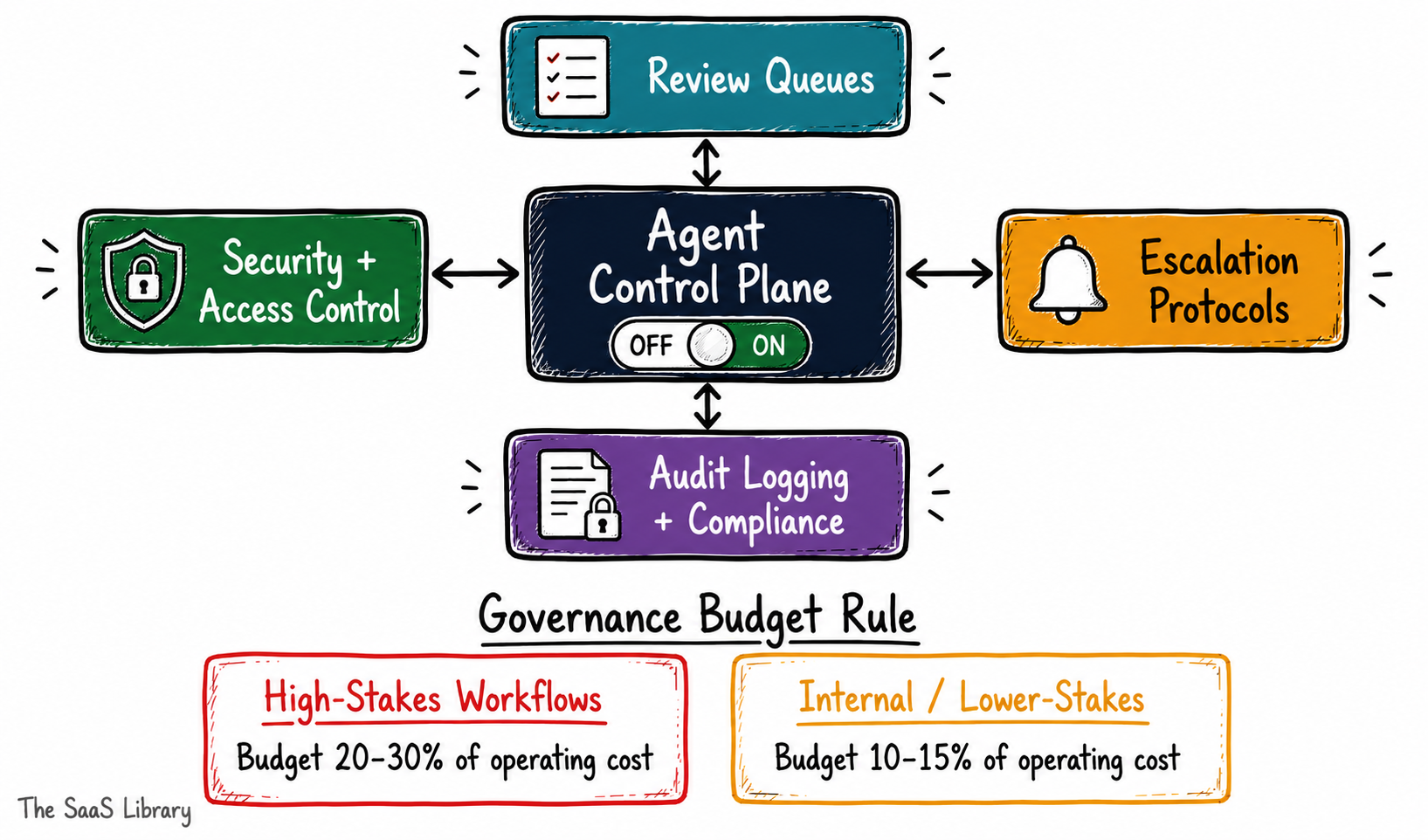
Why Is Layer 4 — Human Oversight and Governance — a Permanent Cost, Not a Transitional One?
When an agent can take action — send an email, update a record, trigger a payment, modify a database — the cost of a wrong decision is no longer just a bad answer on a screen. It’s a live consequence in your systems.
Human oversight for agentic AI isn’t a transitional phase you graduate out of as the technology matures. It’s a permanent cost line — and in 2026, it’s the fastest-growing one in enterprise AI budgets. TSL’s analysis of the governance readiness gap in enterprise SaaS shows most teams build the control plane after the agent is live — not before. That sequence is the most expensive mistake in agentic AI deployment.
Review Queues
For any agent operating in a high-stakes workflow — finance, legal, customer-facing transactions — human review of flagged decisions is non-negotiable. The cost is proportional to your agent’s error rate and the volume of interactions it handles.
Escalation Protocols
Every agent needs a defined path for decisions it can’t make autonomously. Building that path — the logic that triggers escalation, the queue it routes to, the SLA it operates under — is an engineering and operations cost that compounds with agent complexity.
Compliance Monitoring and Audit Logging
Regulated industries — fintech, healthcare, legal — carry compliance requirements that don’t bend for AI autonomy. Every agent action needs to be logged, attributable, and retrievable. Audit-grade logging infrastructure is a non-trivial build, and the ongoing storage cost scales directly with interaction volume.
Security and Access Control
An agent with broad tool access is a broad attack surface. Zero-trust architecture for agentic systems — deterministic capability binding, permission-level memory classification, tool-call scoping — adds both build cost and ongoing security review overhead.
High-stakes workflows touching customer data, financial records, or external communications: budget 20–30% of first-year operating cost for oversight infrastructure. Internal, lower-stakes workflows: 10–15% is a realistic floor — not zero.
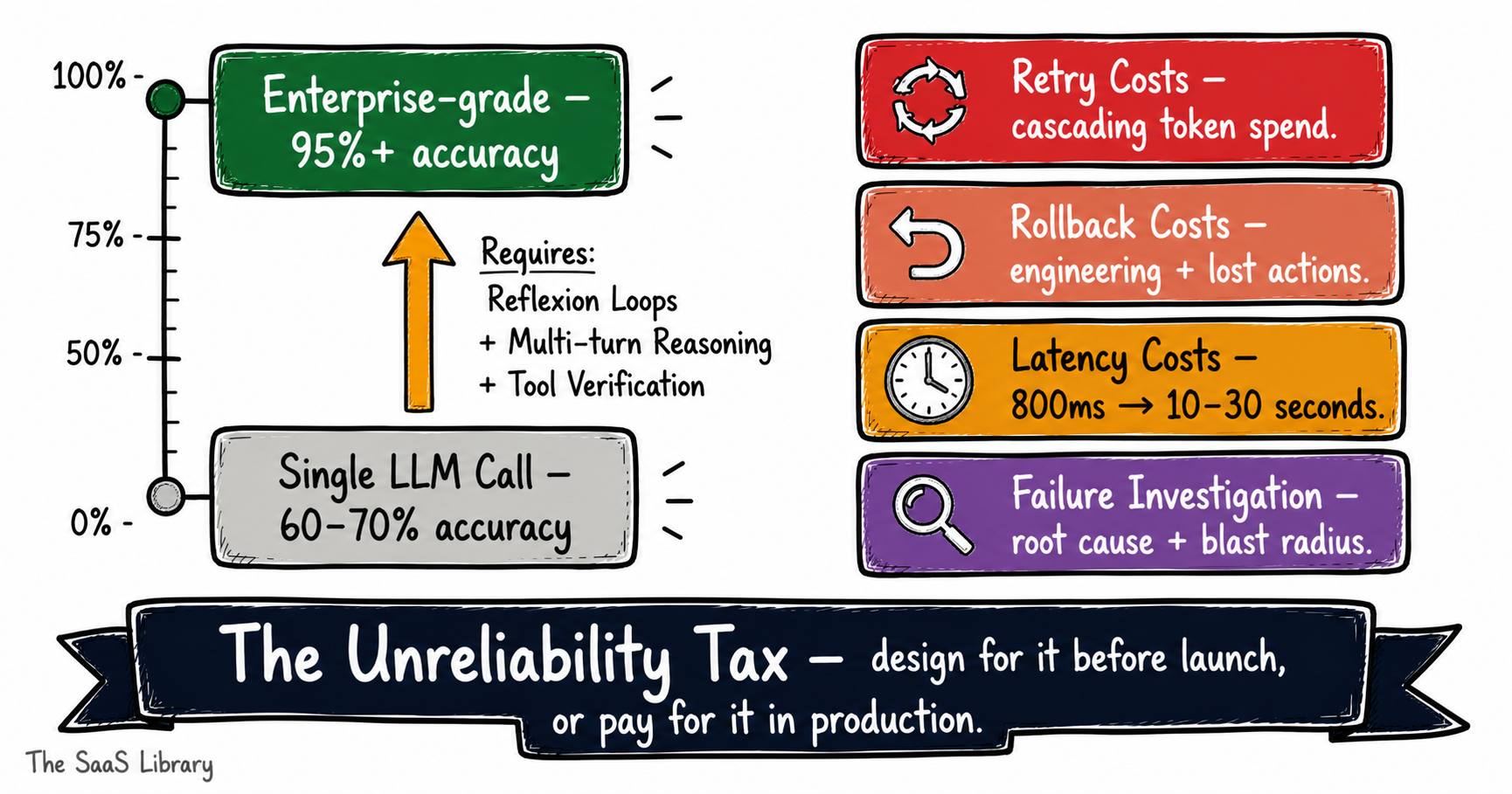
What Is the Unreliability Tax and How Does It Show Up in Your Budget?
Every agentic AI system fails. The question isn’t whether yours will — it’s whether you’ve priced the cost of failure into your budget before it prices itself in for you.
Researchers at Stevens Institute of Technology coined the term Unreliability Tax to describe the hidden cost premium that agentic systems carry precisely because they operate autonomously across multi-step workflows where errors compound rather than isolate.
A single LLM call on a complex task achieves roughly 60–70% accuracy. That’s workable for a copilot. It’s not workable for an agent, where the output of step two becomes the input of step three — and an error at step two propagates silently forward. Achieving the 95%+ accuracy threshold that enterprise processes require means adding multi-turn reasoning, reflexion loops, and tool-call verification at every stage. A single model call takes approximately 800 milliseconds. An orchestrator-worker flow with a reflexion loop takes 10 to 30 seconds. That’s not just a latency problem — it’s a compute cost problem, billed at every retry. Designing for reliability from day one is far cheaper than retrofitting it after the first production failure.
The Unreliability Tax shows up in your budget four ways:
Retry Costs
When a tool call fails, the agent retries. Without exponential backoff and hard retry limits, a single failed request can cascade into hundreds — each consuming tokens, each adding to your API bill.
Rollback Costs
Agents that take real-world actions need rollback capability when a multi-step workflow fails midway. Building reliable rollback logic is a non-trivial engineering investment. Not building it is more expensive.
Latency Costs
For user-facing agentic applications, the 10–30 second response time of a full reflexion loop is often unacceptable. The workaround — routing simpler tasks to faster, lighter models — requires a task classification layer, which is its own build and maintenance cost.
Failure Investigation
When an agent produces a wrong outcome at scale — a systematic error across hundreds of interactions — identifying the root cause, scoping the blast radius, and correcting affected records is an operational cost that dwarfs the original model spend on that workflow.
How Do You Use the AGENT Cost Stack to Estimate Before You Commit?
You now have all five layers. Here’s how to apply them before you spend a dollar. The AGENT Cost Stack is a pre-commitment estimation framework for agentic AI deployments. It forces you to price every layer of real cost — not just the ones on the vendor pricing page — before a project is approved, scoped, or staffed.
If your agent handles fewer than 200 interactions per day on a complex multi-tool workflow, the variable cost of agentic AI will likely exceed the cost of the human workflow it replaces in year one. Start narrower, prove the unit economics at low volume, then scale. Once you have your cost estimate, knowing which AI agent use case to deploy first directly informs which layer of the stack carries the most risk.
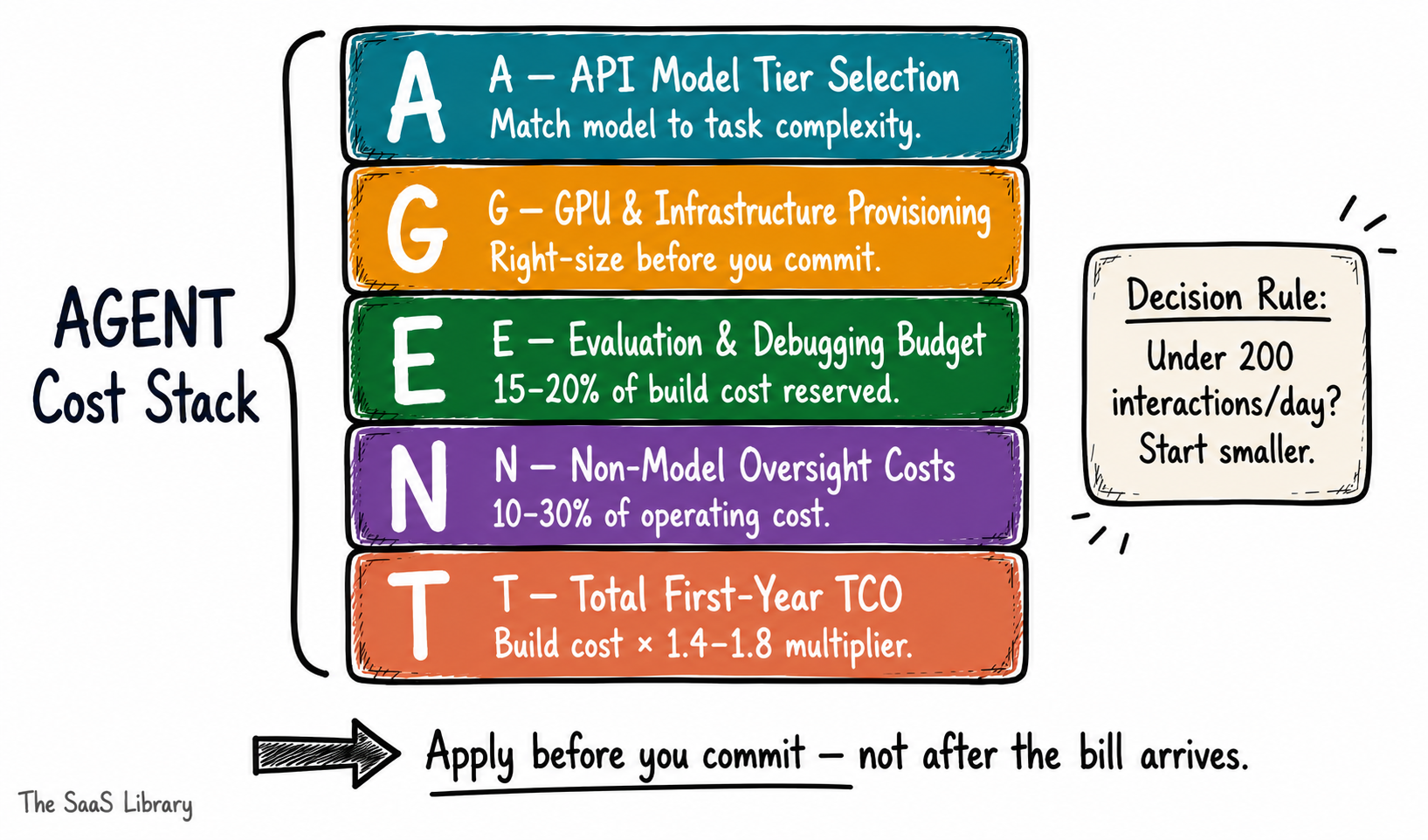
The next step after estimating your cost is picking your first AI agent workflow — the use case with the highest ROI potential and the most manageable cost stack. The teams that blow their agentic AI budgets aren’t the ones who picked the wrong model. They’re the ones who skipped layers G through N entirely.
What Does the ROI Side of Agentic AI Actually Look Like?
Cost without return is just spend. Before you finalise any budget built on the AGENT Cost Stack, you need the other half of the equation.
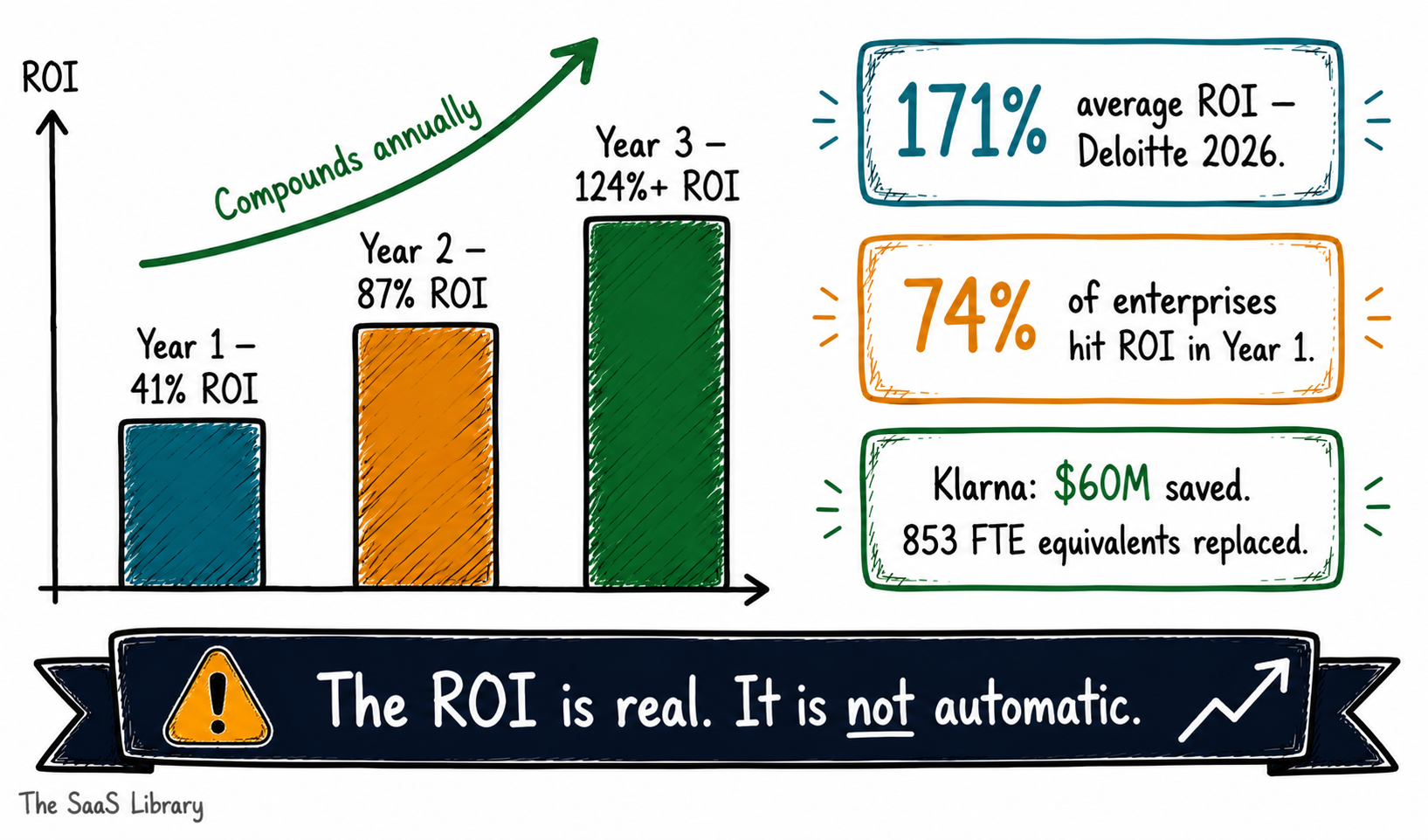
Enterprises deploying agentic AI report an average ROI of 171%, with US enterprises averaging 192%, according to Deloitte’s 2026 State of AI in the Enterprise report. That’s roughly three times the return of traditional automation. Seventy-four percent of organisations hit positive ROI within the first year of deployment. These are production figures drawn from named enterprise deployments across finance, retail, healthcare, and software.
The case studies are specific enough to be useful. Klarna’s customer service agent saved $60 million and replaced the workload of 853 full-time employees by Q3 2025. Salesforce’s Agentforce platform delivered 2.4 billion Agentic Work Units in Q4 fiscal 2026 alone. Companies deploying AI customer service agents report an average return of $3.50 for every $1 spent, with leading organisations reaching 8× ROI. Agentic AI is already reshaping how B2B SaaS companies price and position their products in 2026, and it’s breaking the per-seat SaaS pricing model in the process.
What makes these numbers matter for your budget is the compounding curve. First-year returns average 41%, climbing to 87% by year two, and exceeding 124% by year three for organisations running continuous improvement programs. That trajectory has a direct implication for how you apply the AGENT Cost Stack. A deployment that looks marginal at year-one TCO can be strongly positive at a three-year horizon.
Two caveats worth stating directly. First, the 171% average obscures significant variance — Gartner simultaneously projects that 40% of agentic AI projects will fail to reach production by 2027. The average ROI belongs to the 60% that ship. Second, IDC reports that organisations achieve an average 2.3× return on agentic AI investments within 13 months — but only when tracking all five value metrics: cost savings, productivity lift, revenue impact, avoided costs, and time-to-resolution improvements. Teams tracking only headcount savings consistently undercount their return and underinvest in subsequent deployment.
Frequently Asked Questions
How much does it cost to build an AI agent in 2026?
AI agent development costs range from $15,000 for a focused single-task agent to $400,000 or more for an enterprise-grade multi-agent system with compliance architecture, custom integrations, and orchestration layers. Most mid-market implementations fall between $40,000 and $150,000. That figure covers build cost only — your first-year total cost of ownership typically runs 40–80% higher once infrastructure, integration maintenance, oversight, and failure recovery are included.
What is the total cost of ownership for agentic AI?
Total cost of ownership for agentic AI in year one equals your build cost multiplied by 1.4 to 1.8. A $100,000 build becomes a $140,000 to $180,000 first-year commitment when you account for infrastructure provisioning, evaluation and debugging overhead, governance and oversight infrastructure, and failure recovery costs. The multiplier rises toward 1.8 for multi-agent systems with compliance requirements and deep enterprise integrations.
How do I calculate AI agent token costs for my use case?
Map every step in your agent’s workflow and estimate the token consumption per step — input tokens for context and instructions, output tokens for the agent’s response or action. Multiply your per-workflow token total by your expected daily interaction volume, then apply the per-MTok rate for your chosen model. Add 30% to that baseline to account for caching misses, retry overhead, and the token cost of validation loops. Use that figure as your monthly API cost floor, not your estimate.
What are the hidden costs of agentic AI that most budgets miss?
The four most commonly missed cost layers are infrastructure and orchestration (including idle resource waste of 30–50% from over-provisioning), evaluation pipeline and debugging tooling, human oversight and governance infrastructure, and failure recovery including retry logic and rollback capability. Most pre-commitment budgets include only model API costs — Layer 1 of five. The other four layers typically add 40–80% to first-year spend.
Why do agentic AI projects fail before reaching production?
Gartner projects that over 40% of agentic AI projects will fail to reach production by 2027. The primary causes are evaluation complexity — agents require purpose-built eval pipelines that most teams underestimate — debugging overhead for non-deterministic systems, governance requirements that aren’t scoped until late in the build, and infrastructure costs that exceed what was budgeted at the prototype stage. Failure is rarely a model capability problem. It’s almost always a cost and complexity problem in layers two through five.
Is open-source agentic AI cheaper than using a commercial API?
Open-source models like Meta’s LLaMA 3 eliminate per-token API costs but shift spend to infrastructure — you provision and maintain your own GPU compute, which adds operational complexity and staffing cost. For teams running fewer than 500 interactions per day, managed API pricing is typically cheaper than self-hosted open-source once infrastructure and engineering overhead are factored in. Above 10,000 daily interactions, self-hosted open-source begins to offer meaningful cost advantages — provided you have the engineering capacity to operate it.
How does prompt caching reduce agentic AI costs?
Prompt caching stores frequently repeated input tokens — system prompts, tool schemas, knowledge base context — so the model doesn’t re-process them on every call. Both Anthropic and OpenAI offer approximately 90% off cached input token rates. For agents that load the same context at the start of every session, caching can cut input costs by 50% or more on cache-heavy workloads. It’s the highest-leverage API cost reduction available without changing your model or architecture.
How much should I budget for AI agent governance and oversight?
For agents operating in high-stakes workflows — those touching customer data, financial records, or external communications — budget 20–30% of your total first-year operating cost for governance and oversight infrastructure. This covers review queues, escalation protocol tooling, audit logging, and compliance monitoring. For internal, lower-stakes workflows, 10–15% is a realistic floor. Governance is not a cost you eliminate as the technology matures — it scales with interaction volume and agent autonomy.
What is the Unreliability Tax in agentic AI?
The Unreliability Tax is the hidden cost premium that agentic systems carry because errors in multi-step workflows compound rather than isolate. A single LLM call achieves roughly 60–70% accuracy on complex tasks. Reaching the 95%+ accuracy threshold required for enterprise processes means adding reflexion loops, tool-call verification, and multi-turn reasoning — all of which increase compute cost and latency per workflow. The tax shows up as retry costs, rollback engineering, failure investigation overhead, and the latency workarounds required for user-facing applications.
At what scale does agentic AI become cost-effective?
Agentic AI becomes cost-effective when the cost per automated decision falls below the fully loaded cost of the human decision it replaces — and when interaction volume is high enough to distribute fixed build and governance costs across enough outputs to make the unit economics positive. A useful threshold: agents handling fewer than 200 interactions per day on complex multi-tool workflows will typically cost more in year one than the workflow they replace. Above that threshold, with a well-scoped build and optimised infrastructure, the economics shift meaningfully in favour of deployment.

Conclusion
Agentic AI is not expensive because the technology is immature. It’s expensive because most budgets treat a five-layer cost problem as a one-line item. The AGENT Cost Stack exists to close that gap — map your API tier selection, price your infrastructure, budget your evaluation pipeline, plan your governance costs, and apply the TCO multiplier before you present a number to anyone who has to approve it.
The return is real — 171% average ROI, 74% of deployments paying back in year one, compounding returns through year three for teams that treat this as a continuous program. But that return belongs to the projects that ship. And the projects that ship are the ones that went in with an honest cost picture.
Before you commit, run the Stack. Every layer you skip in estimation, you pay for in production. Ready to decide whether to build or buy? Read our full breakdown: Build vs. Buy an AI Agent: What the 2026 Data Actually Says →
- Decipher Zone — AI Agent Development Cost 2026
- DataRobot — Balancing Cost and Performance: Agentic AI Development, 2026
- Finout — OpenAI vs Anthropic API Pricing Comparison, 2026
- AI Cost Check — Mistral AI Pricing Guide, 2026
- Galileo AI — The Hidden Costs of Agentic AI, 2025
- World Today News — AI Agent Pricing: Anthropic, OpenAI, Google, and Microsoft Diverge, 2026
- Stevens Institute of Technology — The Hidden Economics of AI Agents, 2026
- Gartner — Worldwide AI Spending Forecast, May 2026
- Gartner — 40% of Enterprise Apps Will Feature AI Agents by 2026, 2025
- Tech Insider / Deloitte — Agentic AI in Enterprise 2026: ROI Benchmarks
- AI Monk — Agentic AI Examples with Measurable ROI: Enterprise Case Studies 2025–2026
- Fin.ai — ROI of AI Customer Service: 2026 Benchmarks & Data
- SaaS Mag — How SaaS Companies Are Monetizing AI Agents in 2026
- Neurons Lab / IDC — Agentic AI in Financial Services: 2.3× Return within 13 Months, 2026
- Belitsoft / McKinsey — AI Agent Development Forecast 2026




