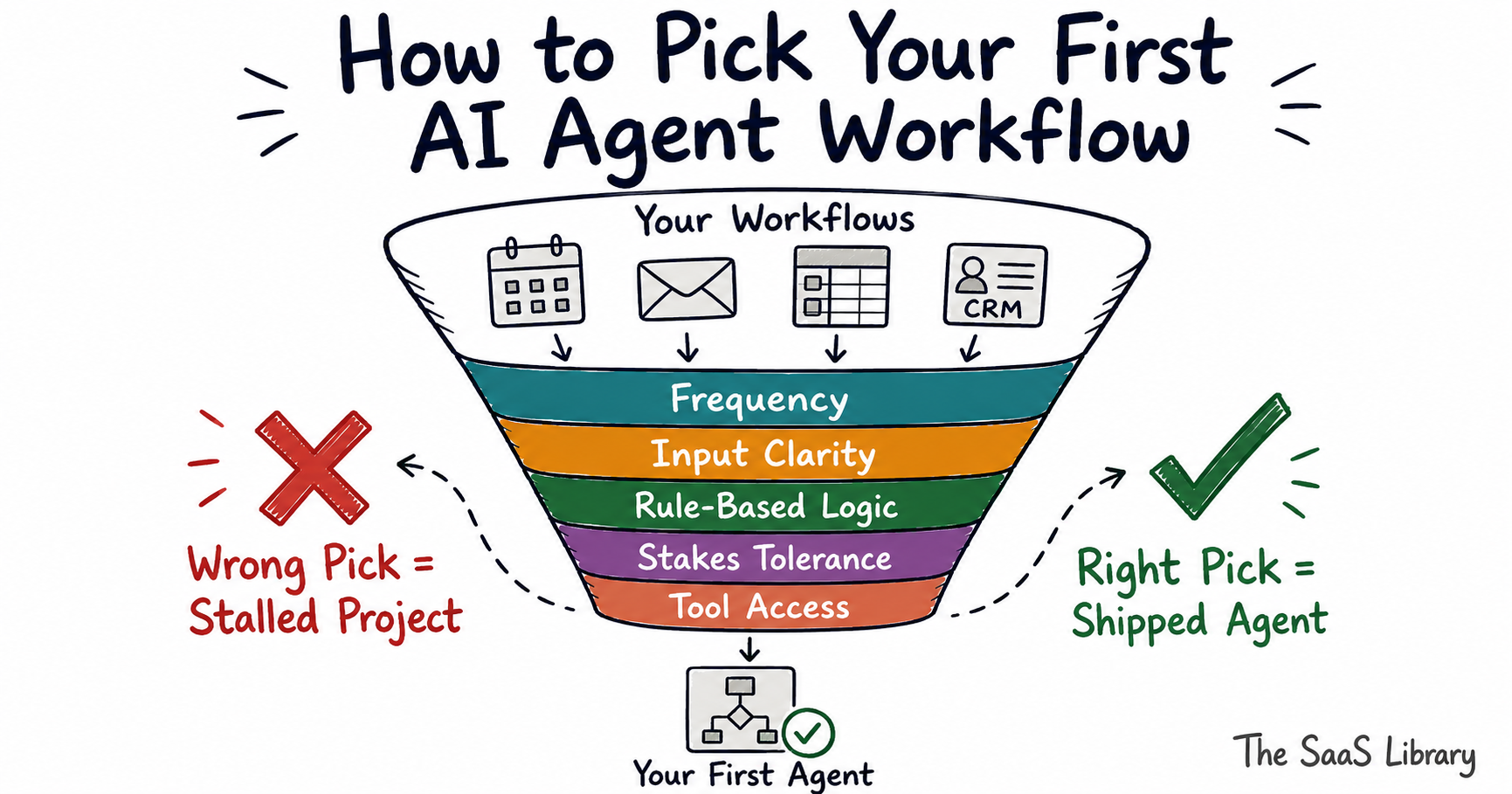
Most teams pick their first AI agent based on what would impress a board. The ones that actually ship — and keep it running — pick based on five signals that have nothing to do with ambition.
Most teams pick their first AI agent based on what sounds impressive in a board update. The ones that actually ship — and keep it running past week three — pick based on readiness signals, not ambition. This guide gives you a five-point scoring framework to identify exactly which workflow in your stack is agent-ready right now, and why starting with the wrong one is the single fastest way to kill internal appetite for every AI project that follows.
Pick the workflow your team runs manually more than three times a week, where the inputs are consistent and the success criteria are measurable. Score it against five signals — frequency, input clarity, rule-based logic, stakes tolerance, and tool access. The workflow that passes all five is your first AI agent. Start there, not with the most exciting use case.
Why Does Your First AI Agent Choice Matter More Than You Think?
Your first AI agent choice matters because it doesn’t just succeed or fail in isolation — it sets the internal credibility of every agent project that follows. A failed first deployment doesn’t get written off as a learning. It gets written off as proof that agents don’t work, and that verdict can freeze an entire organisation’s AI roadmap for months.
According to Landbase’s 2025 agentic AI research, 40% of AI agent project failures trace back to risk management failures — not model quality, not integration complexity, but foundational decisions made before a single line of code was written. Your choice of starting workflow is the most consequential of those decisions.
The problem is that most teams choose based on excitement rather than readiness. The workflow that sounds most impressive in a board update — customer-facing, high-visibility, complex — is almost always the hardest to agent first. The workflows that actually ship are the ones nobody was excited to automate. For context on what agentic AI actually is in B2B SaaS before you pick your starting point, that distinction matters more than most teams realise.
What a Failed First Deployment Actually Costs You
The damage isn’t just the wasted build time. It’s the organisational scar tissue. Teams that experience a failed first agent deployment are significantly more likely to deprioritise subsequent agent projects, revert to manual workflows, and require external proof-of-concept before approving internal builds. The first deployment is a trust event, not just a technical one.
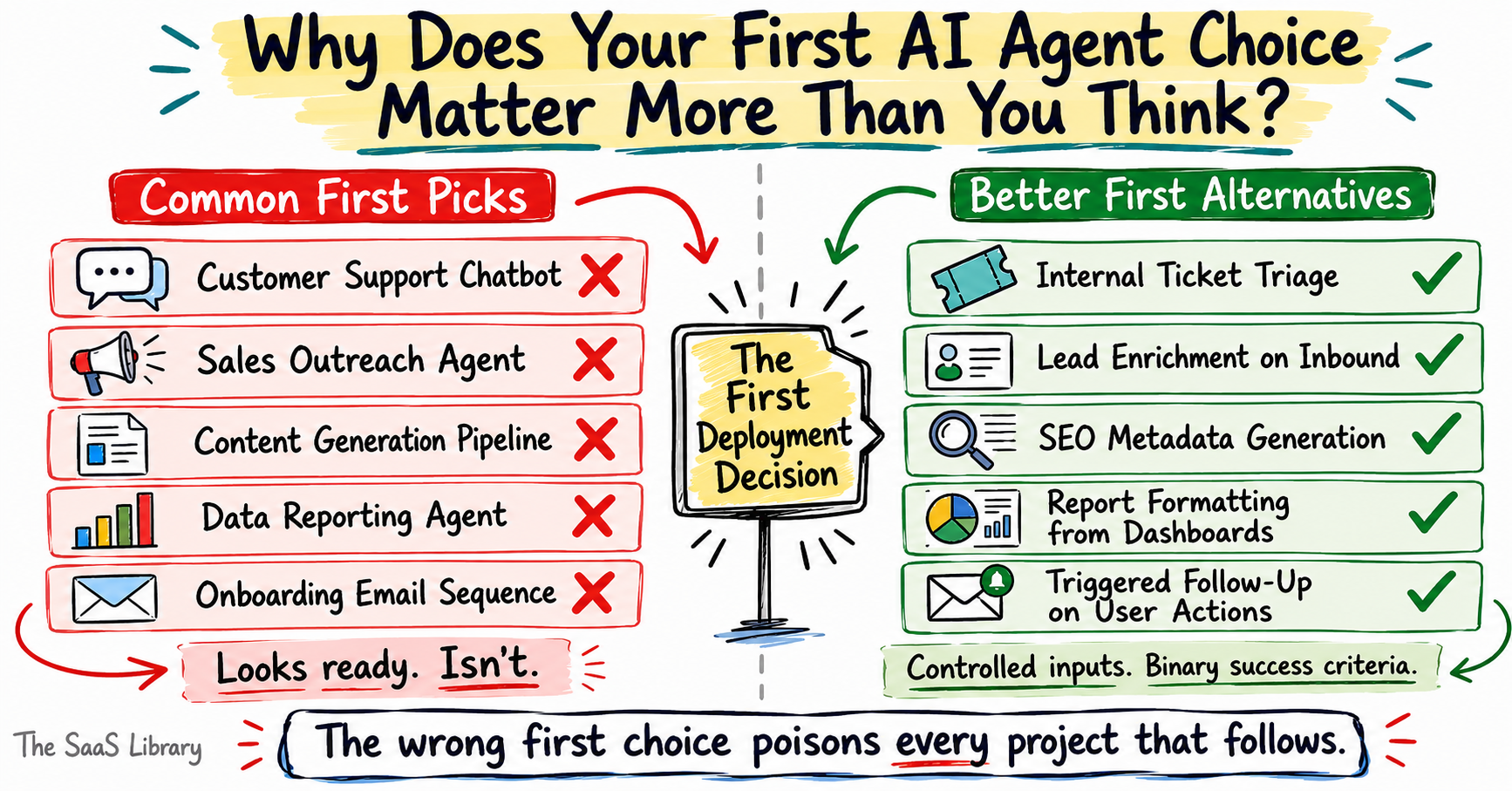
The table below maps the most common first-pick mistakes against better alternatives — and the single reason each common pick fails.
| Common First Pick | Why It Sounds Right | Why It Almost Always Fails | Better First Alternative |
|---|---|---|---|
| Customer support chatbot | High volume, visible ROI | Inputs are unpredictable; edge cases are infinite | Internal ticket triage with defined categories |
| Sales outreach agent | Clear business impact | Requires CRM hygiene most teams don’t have | Lead enrichment on inbound signups |
| Content generation pipeline | Fast to demo | No measurable success criteria; output quality is subjective | SEO metadata generation for existing pages |
| Data reporting agent | Saves analyst hours | Depends on clean, consistent data sources | Scheduled report formatting from fixed dashboards |
| Onboarding email sequence | Repeatable process | Personalisation requirements exceed agent capability at first build | Triggered plain-text follow-up on specific user actions |
The better alternatives in that table share one trait — the inputs are controlled, the logic is articulable, and the success criteria are binary. That combination is what makes a workflow genuinely agent-ready, not its apparent complexity or business impact.
The pattern is consistent: every common first pick fails because it looks agent-ready on the surface while hiding a complexity that only surfaces during build. The distinction — between workflows that appear ready and workflows that are ready — is what the rest of this article is built around. The next section maps the four workflow categories where first agents reliably succeed, and why.
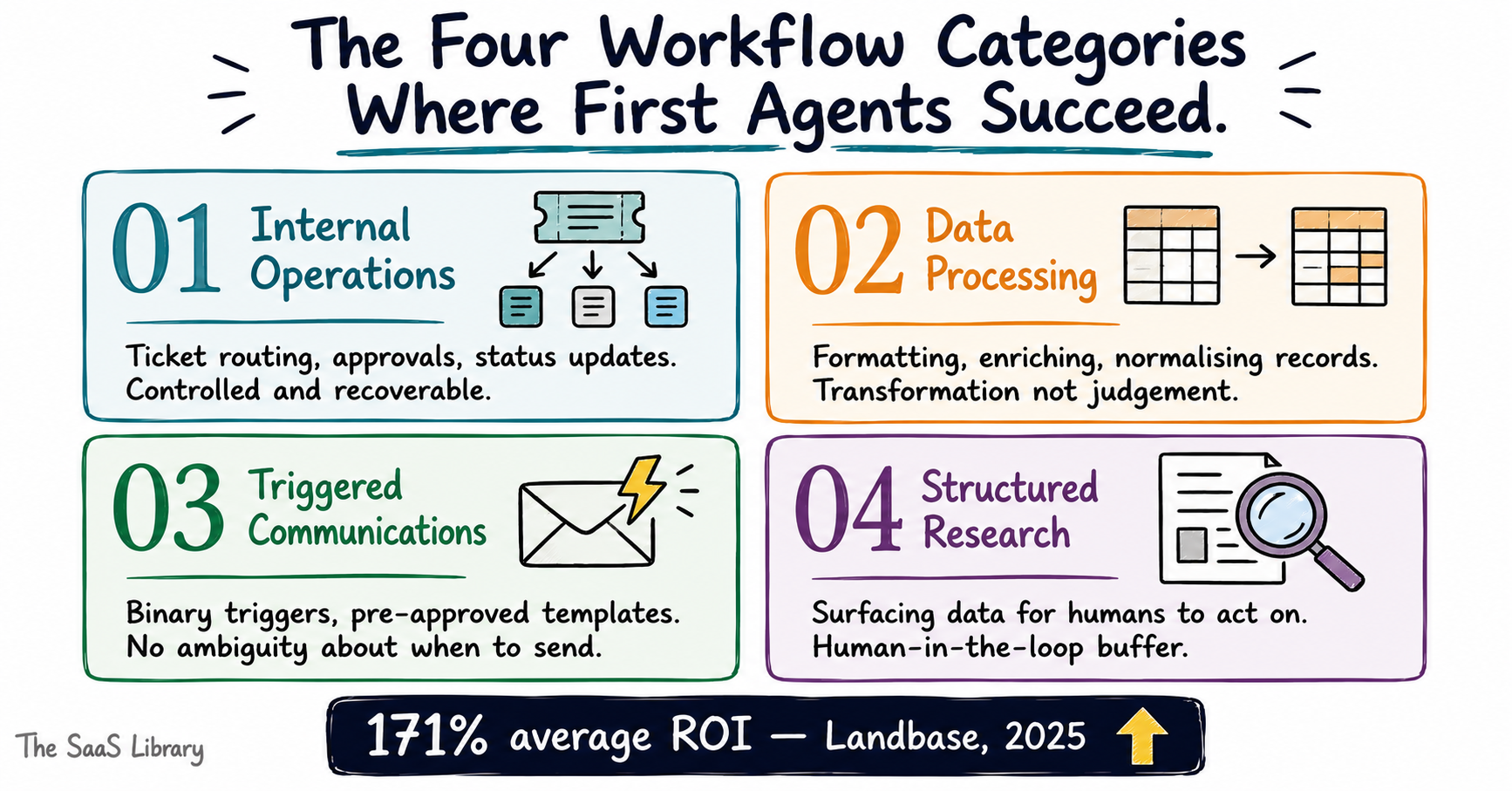
What Are the Four Workflow Types Where First Agents Consistently Succeed?
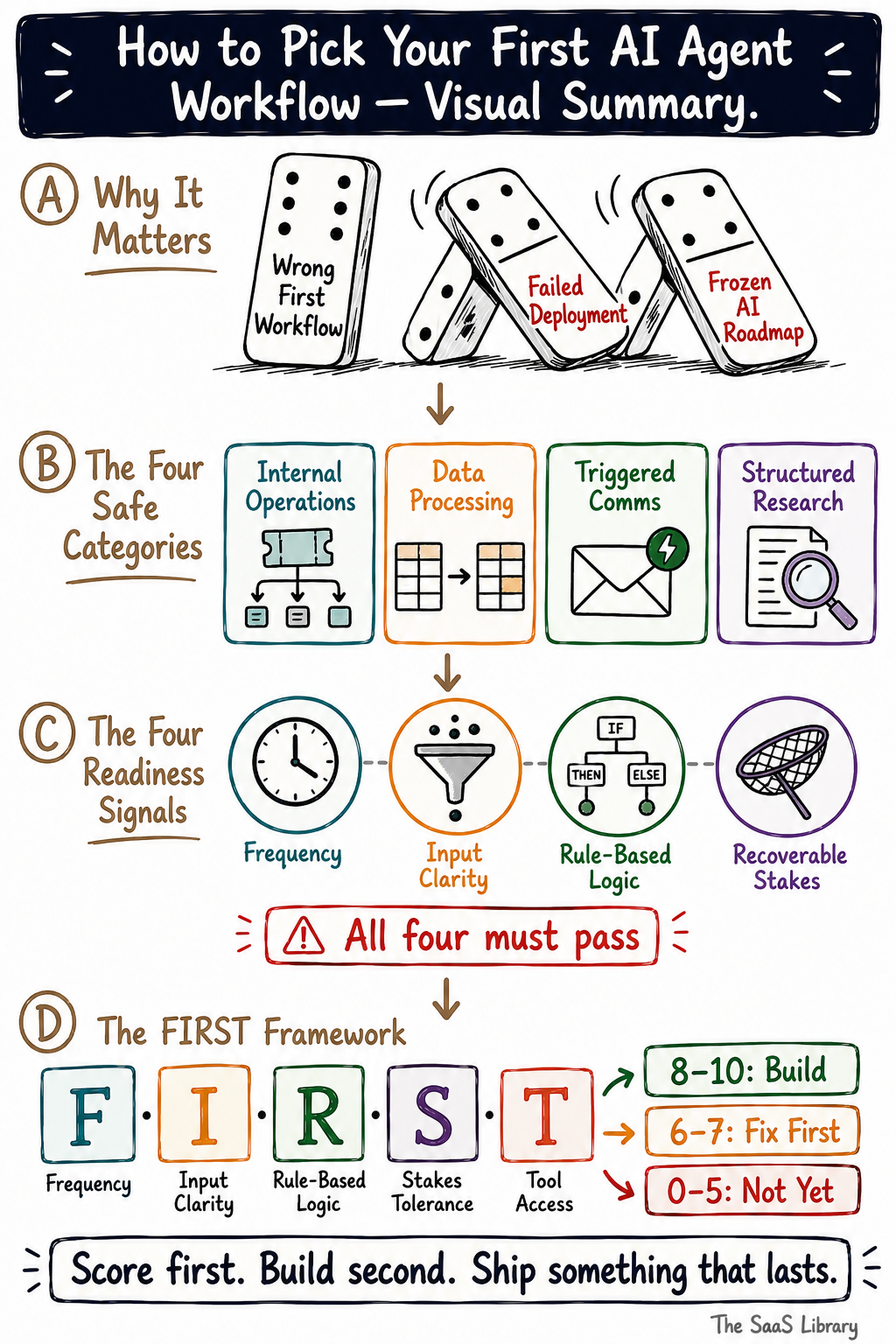
The four workflow types where first agents consistently succeed are internal operations, data processing, triggered communications, and structured research — because all four share the same underlying trait: the inputs are controlled, the logic is rule-based, and the success criteria are measurable before you build.
Most failed first agents don’t fail because the technology isn’t ready. They fail because the workflow wasn’t ready. The four categories below aren’t the most exciting places to deploy an agent. They are the most reliable — and reliability is what your first deployment needs to be.
1. Internal Operations
Internal operations workflows — ticket routing, meeting scheduling, approval tracking, status updates — are the single most consistent category for first agent success. The inputs arrive in a predictable format, the decision logic can be written as explicit rules, and a wrong output is caught immediately by a human who already knows what the right output looks like. That built-in error visibility is what makes this category safe for a first build.
2. Data Processing
Data processing workflows — formatting reports, enriching records, cleaning CRM entries, normalising spreadsheet outputs — succeed because the agent’s job is transformation, not judgement. You give it a consistent input structure, define the output format, and the agent executes the same logic at scale. There is no ambiguity about whether the output is correct.
3. Triggered Communications
Triggered communications — follow-up emails on specific user actions, onboarding nudges tied to product events, renewal alerts based on contract data — work because the trigger is binary and the message template is fixed. The agent isn’t deciding what to say. It’s deciding when a condition has been met and executing a pre-approved action. That constraint is a feature, not a limitation, for a first build.
4. Structured Research
Structured research workflows — competitor monitoring, pricing lookups, lead enrichment from public sources — succeed because the output is informational, not operational. The agent surfaces data for a human to act on. Nothing executes without a review step. That human-in-the-loop buffer makes structured research one of the lowest-risk categories for teams deploying their first agent.
That ROI figure isn’t evenly distributed. It clusters in deployments that started in one of the four categories above — structured, contained, measurable. Teams that started with complex, customer-facing agents reported significantly lower returns and higher abandonment rates in the same dataset.
Not sure if you need an agent or a simpler automation? Read our breakdown of the exact architectural difference.
AI Agent vs Chatbot — What’s the Difference? →If you’re still deciding whether to build or buy your agent infrastructure before you pick a workflow, that decision has its own framework — read our full breakdown before you go further.
You now know which workflow categories give first agents the best odds of success — the next two sections give you the exact signals to evaluate any specific workflow, and the scoring system to make the final call.
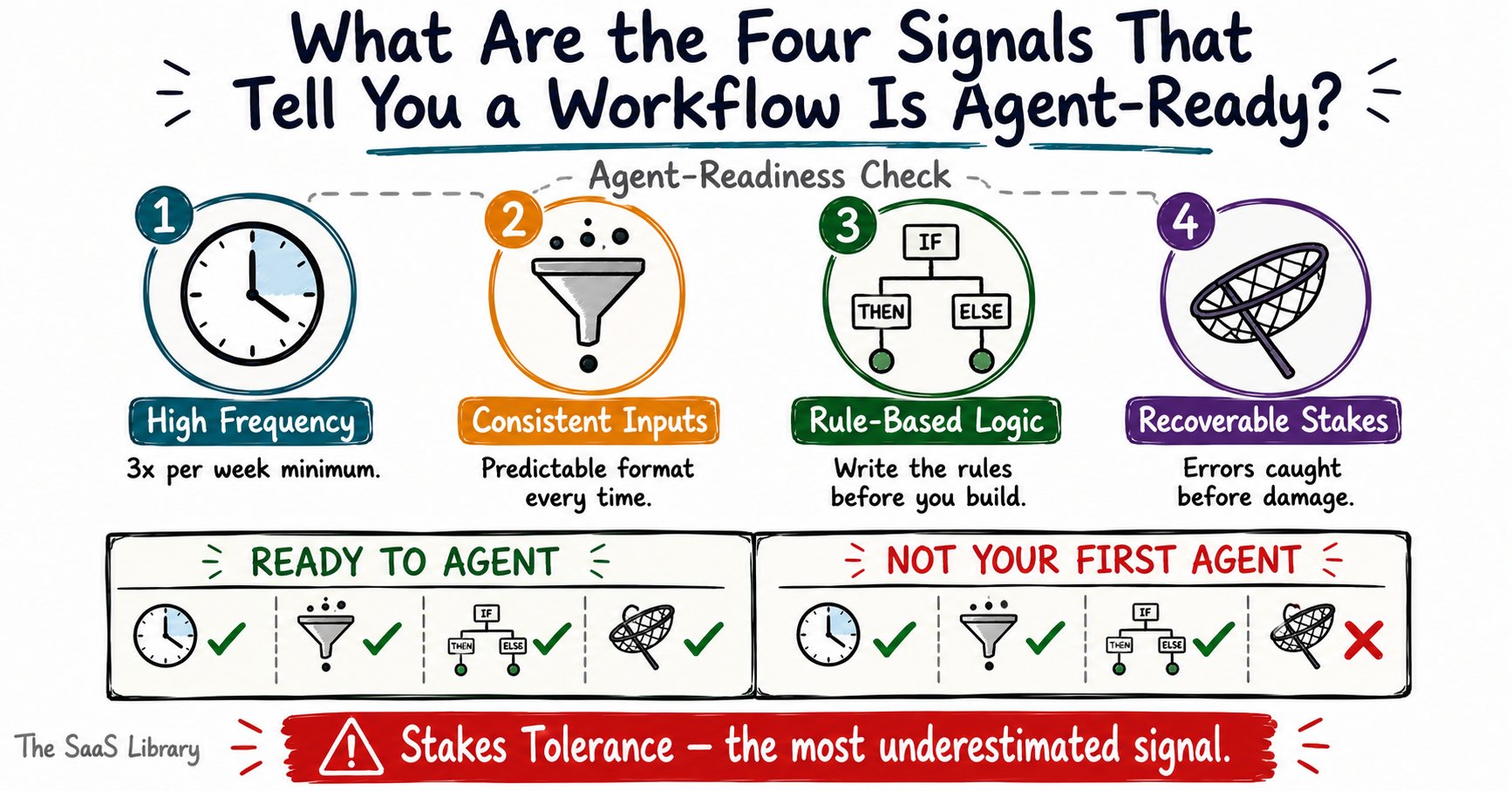
What Are the Four Signals That Tell You a Workflow Is Agent-Ready?
The four signals that tell you a workflow is agent-ready are high frequency, consistent inputs, rule-based logic, and recoverable stakes — and a workflow that fails any one of them will create problems during build that no amount of prompt engineering can fix.
Most teams skip this evaluation entirely. They identify a workflow that sounds automatable, pick a tool, and start building. The signal check takes twenty minutes. Skipping it costs weeks.
Signal 1: High Frequency
High frequency means the workflow runs repeatedly — ideally daily, minimum three times a week. Agents justify their setup cost through volume. A workflow that runs twice a month doesn’t generate enough repetitions to surface edge cases during testing, doesn’t save enough time to demonstrate ROI quickly, and doesn’t give your team enough cycles to improve the agent before stakeholder patience runs out. If the workflow isn’t frequent, it isn’t your first agent.
Signal 2: Consistent Inputs
Consistent inputs means the data or content entering the workflow arrives in a predictable format every time. An agent that processes customer emails requires those emails to carry the same structural signals — subject line patterns, sender fields, body structure — to route correctly. In practice, the most common input consistency failure we see isn’t random variation — it’s teams discovering mid-build that their CRM has three different formats for the same field, populated inconsistently over two years of manual data entry. Your inputs don’t need to be identical. They need to be structurally predictable.
Signal 3: Rule-Based Logic
Rule-based logic means you can write down the decision criteria as explicit if-then statements before you build. If the ticket is tagged “billing,” route to finance. If the lead score is above 80, enqueue for outreach. If the contract end date is within 60 days, trigger a renewal alert. If you cannot articulate the logic as rules before building, the agent cannot execute it reliably after. This is the signal most teams discover they’re missing halfway through a build.
Signal 4: Recoverable Stakes
Recoverable stakes means that when the agent makes a mistake — and it will, especially early — that mistake can be caught and corrected before it causes downstream damage. An agent routing internal support tickets to the wrong queue is recoverable. An agent sending personalised pricing proposals to enterprise prospects without a review step is not. The question isn’t whether your agent will make errors. It’s whether your workflow gives you a window to catch them.
Deloitte’s 2025 Tech Value Survey found that 57% of organisations are directing 21–50% of their digital transformation budgets toward AI automation — yet the same survey shows governance and readiness evaluation as the most commonly skipped pre-deployment step.
| Workflow Category | High Frequency | Consistent Inputs | Rule-Based Logic | Recoverable Stakes |
|---|---|---|---|---|
| Internal Operations | ✅ Usually | ✅ Usually | ✅ Usually | ✅ Usually |
| Data Processing | ✅ Usually | ✅ Usually | ✅ Usually | ✅ Usually |
| Triggered Communications | ✅ Usually | ✅ Usually | ✅ Usually | ⚠️ Check send volume |
| Structured Research | ⚠️ Varies | ✅ Usually | ✅ Usually | ✅ Usually |
| Customer-Facing Support | ⚠️ High but variable | ❌ Rarely | ❌ Rarely | ❌ Rarely |
| Sales Outreach | ✅ Usually | ❌ Depends on CRM quality | ⚠️ Partially | ❌ High reputational risk |
Recoverable stakes is the signal teams most consistently underestimate. A workflow that passes the first three signals but fails on stakes tolerance should never be a first agent — regardless of how much time it would save. The cost of a visible failure at that stage outweighs any efficiency gain.
Running all four signals against a workflow takes under twenty minutes and saves you weeks of misdirected build time. But running them informally — in your head, without a scoring structure — still leaves room for motivated reasoning to override the result. That’s exactly what the FIRST Framework in the next section is designed to prevent.
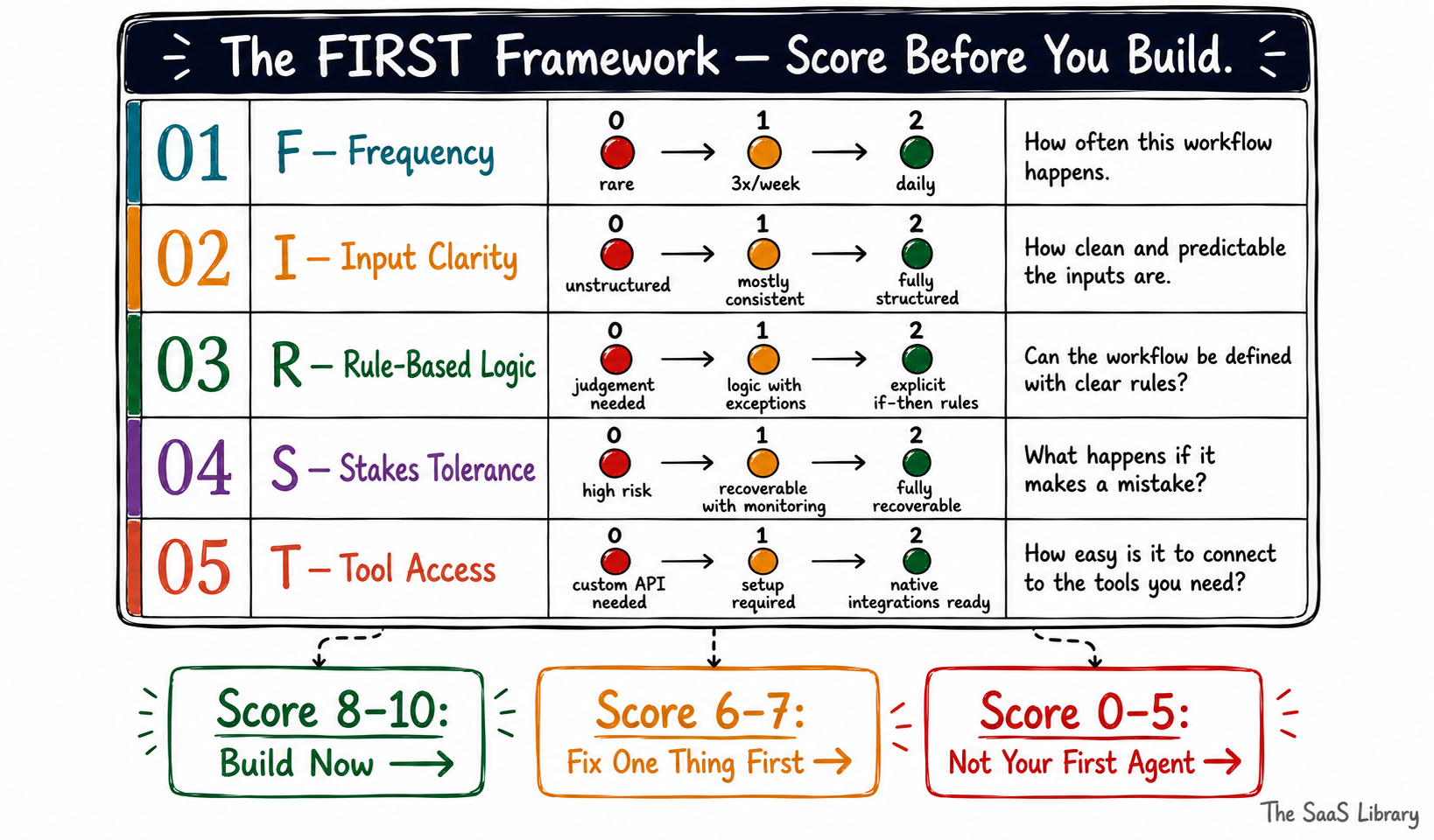
How Do You Score Any Workflow Before You Build? The FIRST Framework
The FIRST Framework is a five-point scoring system that tells you whether a workflow is genuinely ready to agent — before you commit a single hour of build time. Score any candidate workflow against all five criteria. The one with the highest score is where you start.
Most selection decisions fail because they’re qualitative. Someone argues a workflow is “basically rule-based” or “pretty high volume” and the team moves forward on that impression. The FIRST Framework forces the decision into a structure where motivated reasoning can’t quietly override a missing signal.
Each criterion is scored 0, 1, or 2. A workflow that scores 8 or above is agent-ready. A workflow that scores 6 or 7 needs one specific fix before you build. A workflow that scores 5 or below is not your first agent — regardless of how much time it would save.
Apply the FIRST Framework to every workflow you’re considering. The scoring takes under twenty minutes per workflow. When you have scores for three or more candidates, the decision makes itself — the highest scorer is your first agent, and the gap between scores tells you how far behind the others are.
The FIRST Framework doesn’t tell you what your first agent should do. It tells you which workflow in your existing stack is ready to become one — right now, with the data quality, integrations, and risk tolerance you already have. That distinction is what separates agent projects that ship from agent projects that stall. For a deeper look at how most teams lose control of agents once they’re in production, understanding readiness before build is only half the picture.
Gartner forecasts 40% of enterprise applications will include task-specific AI agents by end of 2026 — up from under 5% in 2025. The teams already running agents aren’t more technically advanced. They started with a workflow that was ready. — Gartner, August 2025.
The FIRST Framework gives you a score. The next step is using that score to make the actual decision — and knowing what to do with workflows that score in the grey zone. That’s what the FAQ covers, along with the most common questions teams have at exactly this stage of the process.
Frequently Asked Questions
What is an AI agent workflow?
An AI agent workflow is a sequence of tasks where an AI model makes decisions, calls tools, and takes actions autonomously to complete a goal — without a human approving every step. Unlike a standard automation, an agent can handle conditional logic, adapt to variation in inputs, and chain multiple actions together in a single run. The key distinction is that the agent decides what to do next based on the result of the previous action, not a fixed script written in advance.
How do I pick my first AI agent workflow?
Pick the workflow in your stack that scores highest across five criteria: frequency, input clarity, rule-based logic, stakes tolerance, and tool access. The workflow that runs most often, receives consistent inputs, follows articulable decision logic, tolerates recoverable errors, and uses integrations you already have is your first agent. Start there — not with the workflow that would save the most time if it worked perfectly.
What makes a good first AI agent use case?
A good first AI agent use case is high-volume, rule-based, and internally facing. It should run at least three times a week, receive inputs in a consistent format, follow logic you can write as explicit if-then statements, and produce errors that a human can catch before they cause damage. Internal ticket routing, lead enrichment, scheduled report formatting, and triggered follow-up emails are the most reliable starting categories.
What is the difference between an AI agent and automation?
Automation executes a fixed sequence of steps you define in advance — every run follows the same path. An AI agent has a reasoning loop: it perceives the current state, decides what action to take, executes it, observes the result, and adapts before taking the next step. The practical difference is that automation breaks when inputs vary from the expected pattern, while an agent can handle variation within the boundaries of its training and instructions.
How long does it take to build a first AI agent?
A first AI agent built on a no-code platform like n8n, Make, or Zapier typically takes between one and three days to reach a testable version. A framework-based build using LangChain, CrewAI, or the OpenAI Agents SDK takes one to two weeks for a production-ready version. The build time is rarely the bottleneck — workflow selection, data preparation, and integration setup account for most of the total time investment.
What are the most common reasons AI agent projects fail?
The most common reasons AI agent projects fail are poor workflow selection, inconsistent input data, and undefined success criteria. According to Landbase’s 2025 agentic AI research, 40% of project failures trace back to risk management decisions made before build began — not model quality or integration complexity. Teams that skip the readiness evaluation stage and start with a complex, customer-facing workflow account for the majority of stalled first deployments.
Should I start with a customer-facing or internal AI agent?
Start with an internal AI agent. Customer-facing agents expose your first deployment to unpredictable inputs, reputational risk, and edge cases that are difficult to anticipate during a first build. Internal agents — routing tickets, enriching records, formatting reports — give you a controlled environment to test, iterate, and build organisational confidence before any external exposure. Move to customer-facing workflows only after your team has shipped and stabilised at least one internal agent.
What AI agent tools are best for a first deployment?
For non-technical teams, n8n, Make, and Zapier offer visual builders that can produce a working first agent in under a day. For technical teams, LangChain and CrewAI offer full control with Python-based builds suited for production deployments. The right tool depends on your team’s technical capacity, not the complexity of the workflow — start with the tool your team can operate independently, because you will need to iterate after the first version ships.
How do I know if my AI agent is working correctly?
Define your success criteria before you build, not after. A working AI agent produces outputs that match what a human would produce on the same input, within an acceptable error rate you set in advance. For a first deployment, an error rate under 5% on a representative sample of inputs is a reasonable threshold. Monitor the first 100 outputs manually, log every error by type, and use that data to identify whether errors are systematic — indicating a logic problem — or random — indicating an input quality problem.
What should I do after my first AI agent is live?
After your first AI agent is live, spend the first two weeks monitoring outputs manually and logging every error before expanding the workflow’s scope or automating additional steps. Use the error log to identify the most common failure pattern and fix that single issue before adding complexity. Once the agent is stable — defined as fewer than 5 errors per 100 runs for two consecutive weeks — apply the FIRST Framework to your next candidate workflow and begin the selection process again.
Conclusion
The FIRST Framework exists because the most expensive mistake in an AI agent project isn’t a bad build — it’s a bad starting point. Score your workflows before you commit. Pick the one that’s ready, not the one that’s exciting. Ship something that works, build internal confidence, then expand.
Your first agent sets the credibility of every agent project that follows. Make it the one that succeeds.
Ready to go deeper? Read our full breakdown of AI agents already running in SaaS to see exactly what a production-ready deployment looks like.
- Landbase — Agentic AI Statistics, 2025
- Gartner — 40% of Enterprise Apps Will Feature Task-Specific AI Agents by 2026, August 2025
- Deloitte — Tech Value Survey, TMT Predictions 2026
- The SaaS Library — Agentic AI in B2B SaaS: Production vs. Hype
- The SaaS Library — Build vs. Buy an AI Agent: What the 2026 Data Actually Says
- The SaaS Library — AI Agents in SaaS: 8 Use Cases You Can Deploy Right Now
- The SaaS Library — 96% of Companies Are Running AI Agents. Only 21% Can Control Them.





