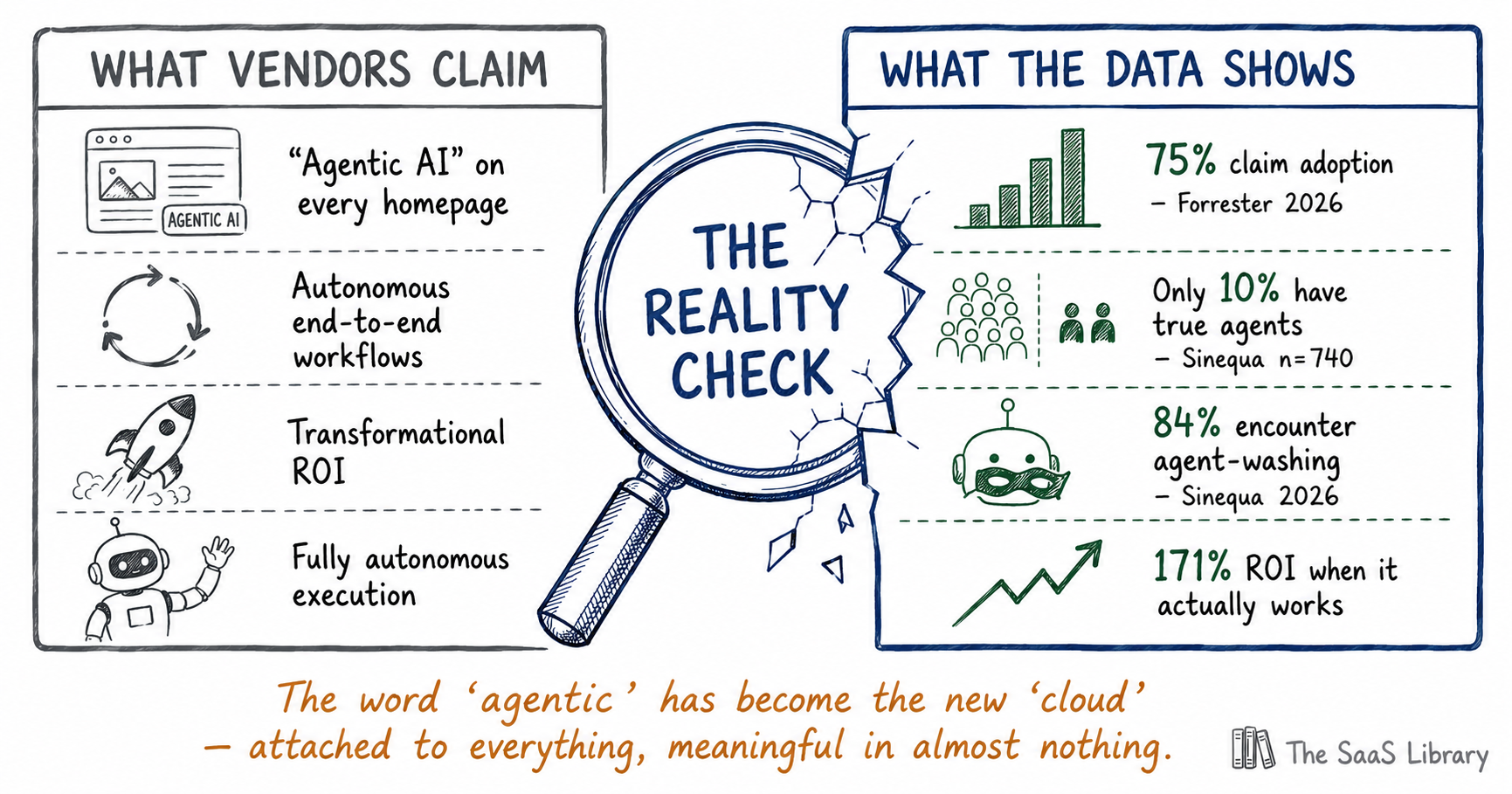
Every SaaS vendor in 2026 calls their product “agentic.” It’s on every homepage, every pitch deck, every press release. And Forrester’s data says three-quarters of enterprises are “adopting” it — yet only a fraction have anything real running beyond a chatbot with a better job title.
The word “agentic” has been detached from its meaning at exactly the moment when the actual technology is producing some of the most dramatic enterprise results ever documented. That gap — between the label and the reality — is what this article is about. If you can’t tell the difference between true agentic AI and a sophisticated chatbot wearing the costume, you’ll either buy the wrong thing, build the wrong roadmap, or misdiagnose why your deployment is failing. This piece names the gap, documents what’s real, and gives you a test to apply to whatever you’re currently running. See also: What Is the Difference Between an AI Agent and a Chatbot?
There’s a term for what’s happening across the market. We’re calling it agent-washing — and it’s worth defining precisely before we go further.
What Does “Agentic” Actually Mean — and Why Does the Definition Matter?
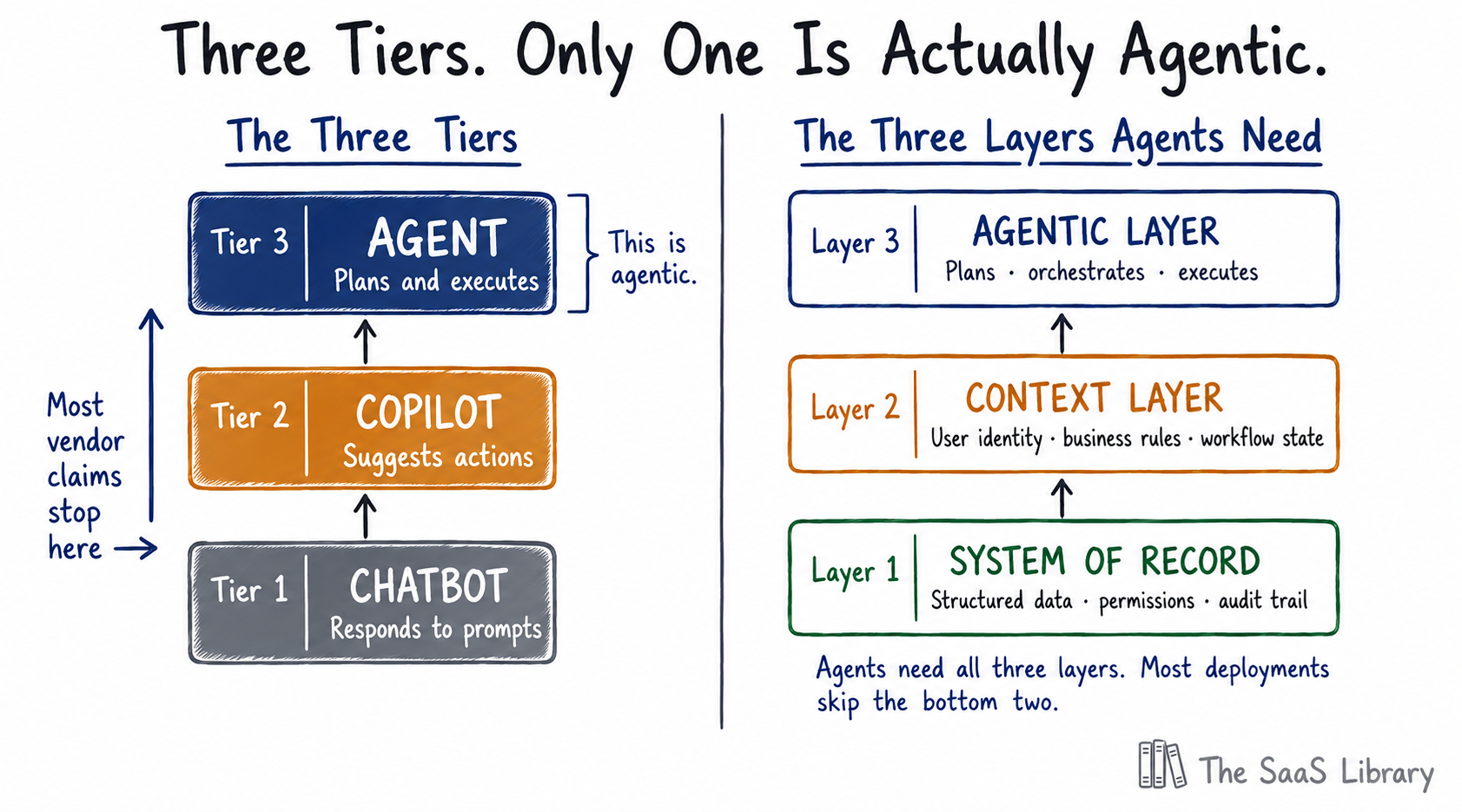
Most vendors mislabel. Before any data about the market means anything, the definition has to be precise. Agentic AI refers to software that can autonomously plan and execute multi-step tasks — not just answer questions (that’s a chatbot), and not just suggest next actions (that’s a copilot). True agents act. They initiate, orchestrate, and adapt. The shift from “assists humans” to “acts on behalf of humans” is what makes this architecturally distinct — and what most vendor claims don’t survive on examination.
A useful framework for thinking about this comes from Cathay Capital’s portfolio research on the evolution of enterprise software. True agentic AI requires three layers working together: a System of Record at the base (structured data, permissions, audit trail, compliance), a Context Layer in the middle (user identity, business rules, workflow state), and the Agentic Layer on top — the System of Action where agents plan, orchestrate, and execute. The critical insight is that agents cannot function without the bottom two layers. Most vendor pitches show you only the top. Most enterprise deployments fail because the bottom two aren’t ready.
The taxonomy of agent types that’s emerging in practice clarifies the distinction further. Copilots assist users within existing workflows — they’re not agents. Wedge agents own a specific job end-to-end. Sentinel agents continuously monitor data and flag issues. Orchestrators execute complex multi-step workflows across tools. Most “agentic AI” marketing describes copilot behaviour at best. True orchestrators — the kind producing the ROI numbers in the next section — are architecturally different from a language model with a chat interface.
Why does this distinction matter commercially? If you can’t tell the difference, you will buy the wrong thing, build the wrong roadmap, and misdiagnose why your deployment is failing. The word “agentic” has become a marketing category rather than a technical specification. Reclaiming the definition is the prerequisite for everything else.
How Much of the “Agentic AI” Market Is Real in 2026?
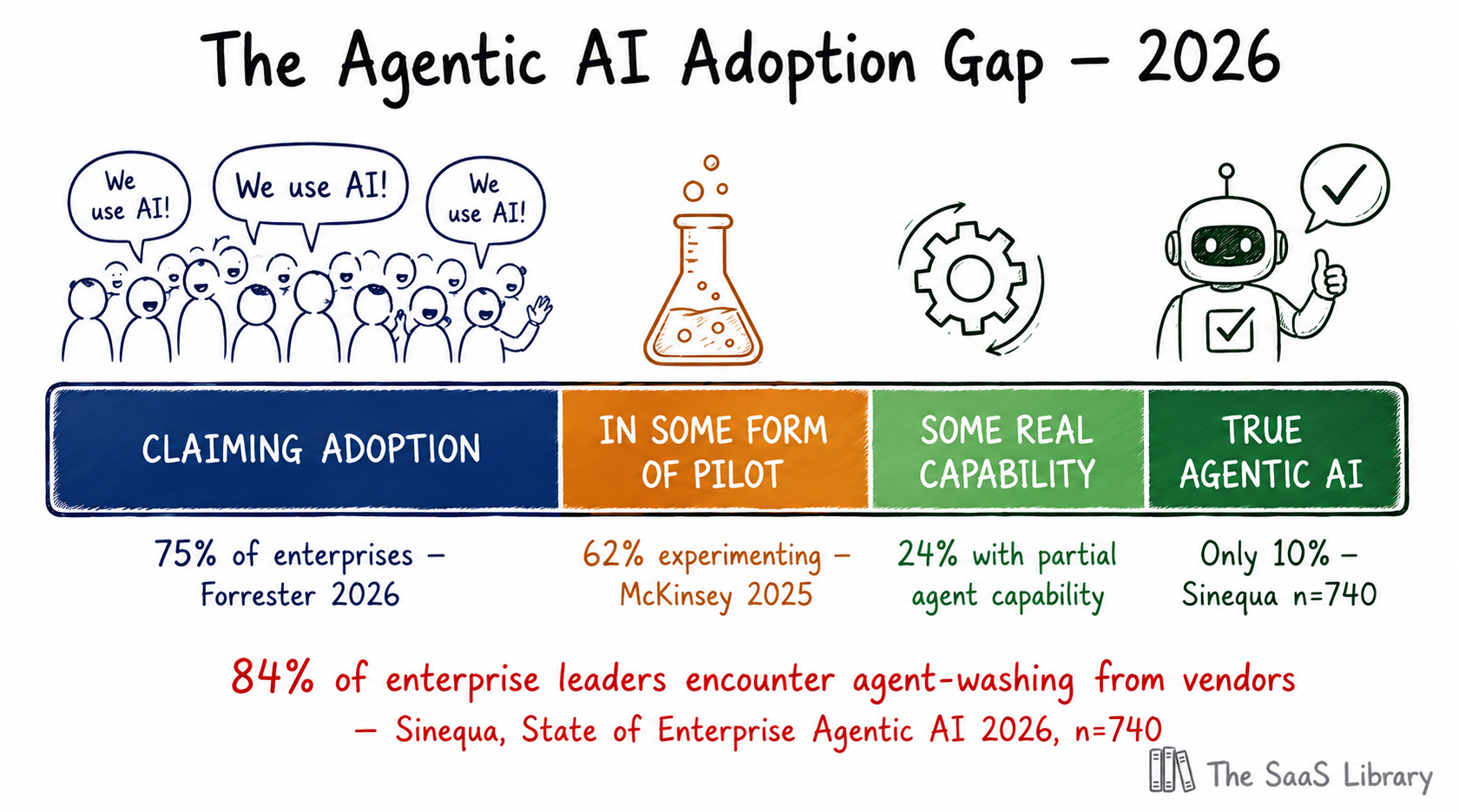
The adoption claim versus the production reality is the central tension of the market right now. Forrester’s State of Agentic AI, 2026 found that 75% of enterprise leaders say they are adopting agentic AI, but only a small fraction have it running in meaningful production beyond “agentish” chatbots. This is not a niche problem — it is the defining condition of the market.
Sinequa’s enterprise research (n=740, $1B–$20B+ revenue companies) found that 51% claim production deployment, but only 24% have anything qualifying as genuine agent capability, and only 10% have true agentic AI deployed at meaningful scale. McKinsey’s data reinforces this: 62% of enterprises are experimenting, but fewer than 25% have scaled to production. Gartner placed AI agent development platforms at the Peak of Inflated Expectations in April 2026, and projects that 40% of agentic AI projects will be put on hold by end of 2027 due to rising costs, unclear business value, and insufficient risk controls.
The label has outrun the reality. But where the reality does exist, the numbers are genuinely extraordinary — and the gap between the two is the most important commercial signal in enterprise AI right now.
Where Is Agentic AI Actually Delivering ROI?
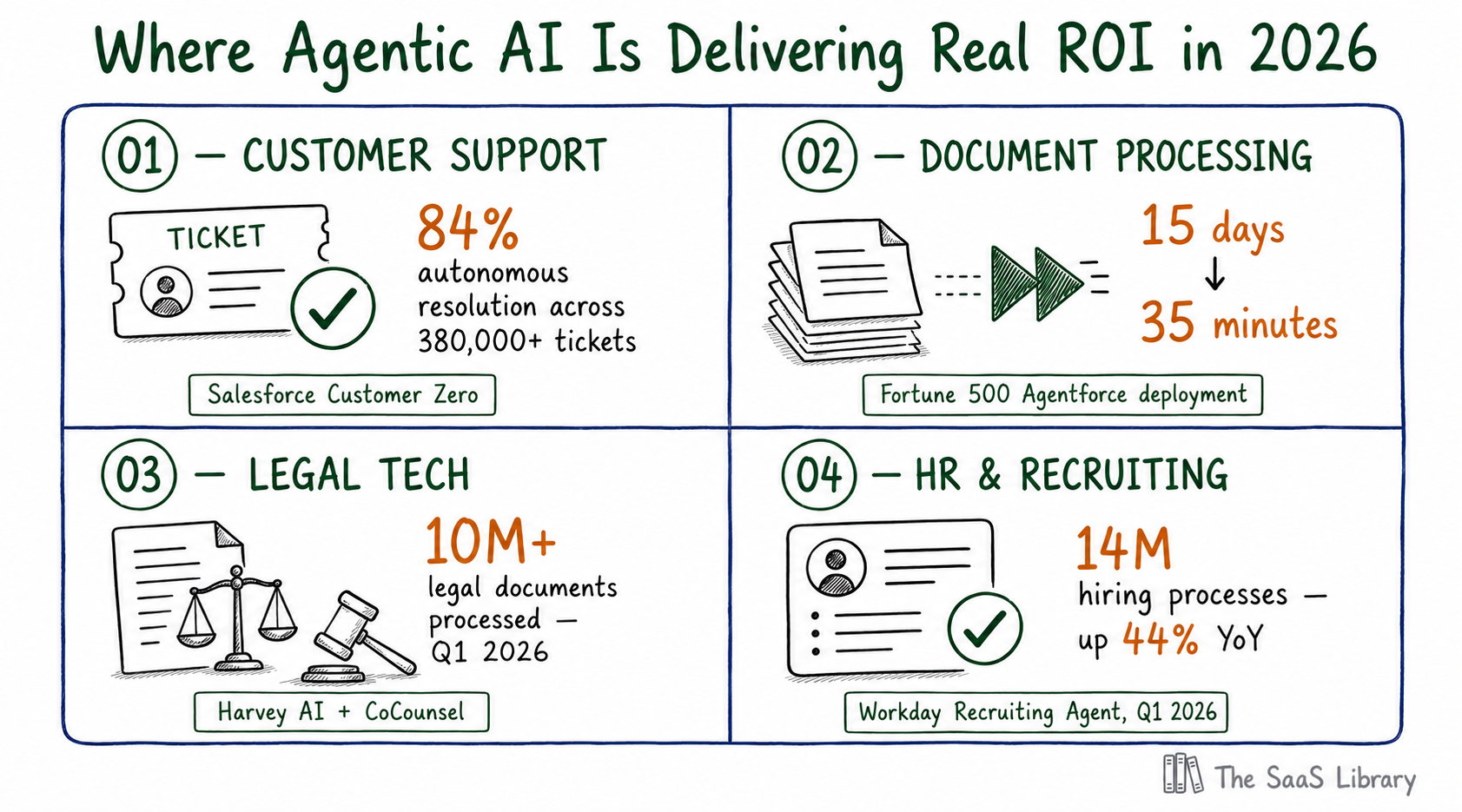
The pattern across every successful production deployment is consistent: task-specific, high-volume, well-defined workflows. Not open-ended autonomy — narrow and deterministic execution of processes that were previously manual and repetitive. Every documented case of genuine production ROI shares this characteristic. See also: AI Agents in SaaS: 8 Use Cases You Can Deploy Right Now
Customer support has the strongest evidence. Salesforce’s own Agentforce deployment handled over 380,000 customer support interactions and resolved 84% of cases autonomously, requiring human escalation for only 2%, while removing $100 million from the support function. Intercom’s Fin AI agent reached nine-figure ARR at $0.99 per resolved ticket — outcome-based pricing that only works when the agent actually delivers. That pricing signal matters: vendors confident enough to charge per result, not per seat, are demonstrating a kind of proof that marketing claims cannot replicate.
Legal tech and document processing tell the same story. A Fortune 500 enterprise using Agentforce cut reporting time from 15 days to 35 minutes while dropping cost per report from $2,200 to $9. Harvey AI processed more than 10 million legal documents in Q1 2026 — 80 of the AmLaw 100 now use it, up from 15 eighteen months ago. HR and recruiting add a third domain: Workday’s Recruiting Agent supported 14 million hiring processes in Q1 alone, up 44% year-over-year.

Why Are Most Companies Stuck in Pilot Purgatory?
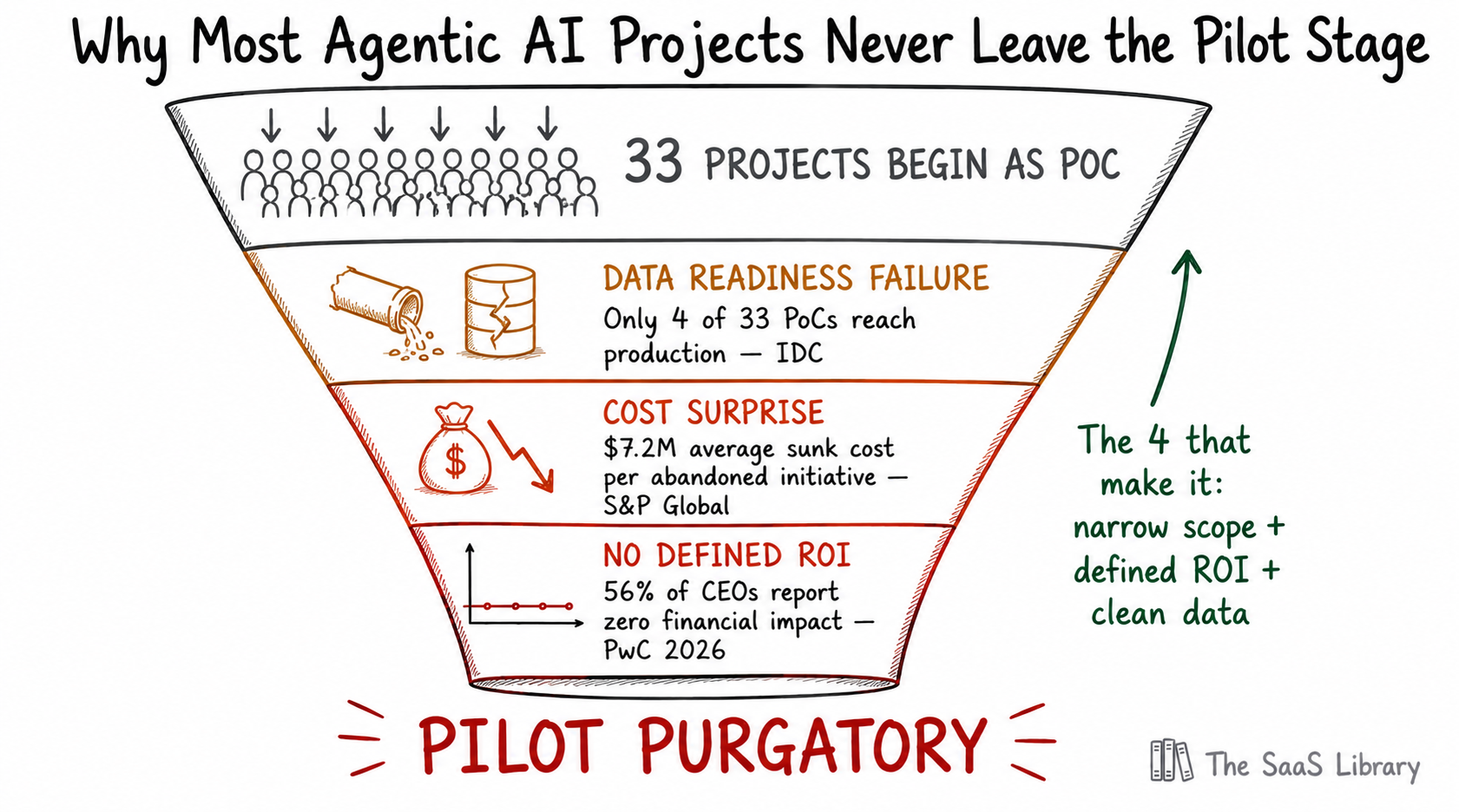
The failure rate is not a commentary on the technology. It is a commentary on the organisational conditions into which that technology is being deployed. IDC research found that for every 33 AI proofs of concept an enterprise starts, only four ever reach production. S&P Global data shows large enterprises abandoned an average of 2.3 AI initiatives in 2025 alone, each carrying an average sunk cost of $7.2 million. PwC’s 2026 CEO Survey found that 56% of CEOs report no financial impact from AI investment despite broad adoption.
Root cause one: data readiness. Agents need clean, structured, accessible data. Most enterprise data is fragmented across warehouses, SaaS platforms, and legacy systems. The pilot works on a curated slice — production breaks on the real thing. Root cause two: orchestration complexity. Single-agent architectures fail at scale. Real deployments require multiple coordinated agents with shared registries and routing. Scaling fails on task complexity, not agent count. Root cause three: undefined ROI. Enterprises that define specific outcome metrics before deployment report 171% average returns. Those that don’t rarely sustain investment past 12 months. See also: 96% of Companies Are Running AI Agents. Only 21% Can Control Them.
By the third failed pilot, executives stop attending reviews — and the fourth pilot launches into an organisation that has already decided, implicitly, that AI does not work here. Pilot purgatory is not a neutral state. It is a compounding problem.
What Separates the Companies That Have Scaled From the Ones That Haven’t?
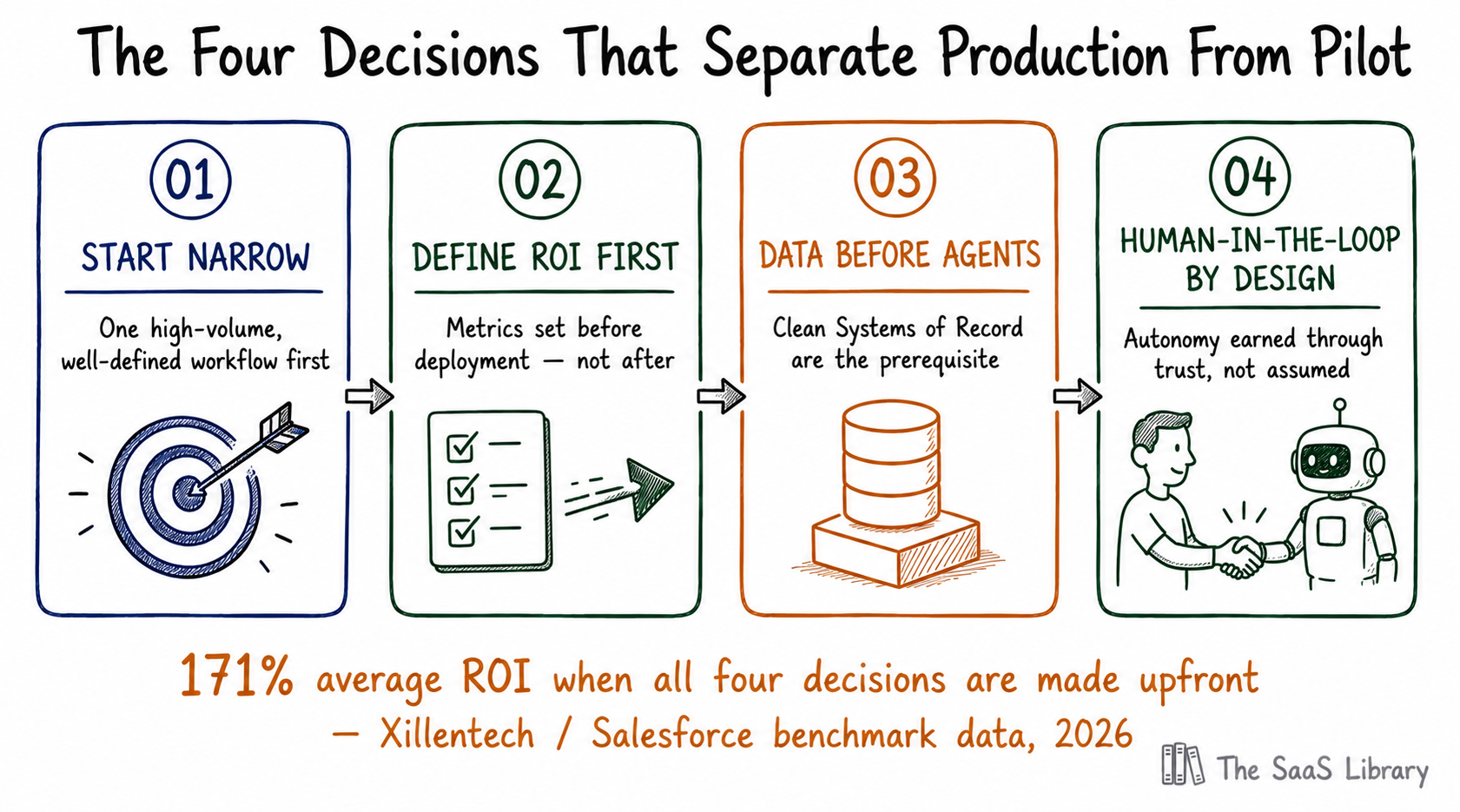
The pattern across every documented successful deployment is consistent — it is not budget size, vendor choice, or model quality. It is the order in which decisions were made, and the discipline to hold to that order when pressure builds to move faster.
Decision one: start narrow. Every enterprise producing real ROI chose one high-volume, well-defined workflow first, proved the ROI, and expanded from there. Harvey AI’s law firm deployments make this concrete: the firms that succeeded picked one workflow (contract review or due diligence), proved value, then expanded. Those that tried to deploy broadly first failed. Decision two: define success before deploying. Enterprises that set specific outcome metrics before deployment report 171% average ROI. Those that don’t rarely survive the 12-month review. Decision three: treat Systems of Record as foundation, not obstacle. Agents need structured data, business rules, and permissions — all of which live in Systems of Record. The enterprises building the agentic layer on top of clean, governed systems are the ones producing deterministic, reliable outputs. See also: Agentic AI Optimization
Decision four: design human-in-the-loop from day one. Workday’s framing is precise: AI that understands people, policies, and processes well enough to take action while keeping humans in charge. That last clause is not a hedge — it is the architecture. Autonomy earned incrementally through demonstrated reliability is how trust is built into an AI system. Assuming maximum autonomy from deployment is how trust is destroyed. See also: The Governance Readiness Gap — AI Compliance for Enterprise SaaS
The enterprises producing real ROI from agentic AI share one trait: they treated deployment as an organisational decision, not a technology procurement. The model was the easy part. The data readiness, the defined outcome, the narrow scope — those were the hard parts. And they did them first. See also: 96% of Companies Are Running AI Agents. Only 21% Can Control Them.
So Is Your Company Actually Deploying Agentic AI — or Just Calling It That?
The agent-washing problem compounds because most organisations cannot tell from the inside whether what they have deployed qualifies as agentic AI. The label comes from the vendor. The architecture is rarely explained. And the incentive structure of enterprise software procurement does not reward vendors for being precise about what their software cannot do.
Six questions separate true agentic deployments from sophisticated automation wearing the label. These are not vendor questions — they are deployment questions. The answers come from your own system behaviour, not from your vendor’s marketing materials. Use The Agent-Washing Test below to diagnose where you actually sit. See also: llms.txt and Sitemaps Explained — on making your infrastructure legible to agents in the agentic web.
The three outcomes from this test have clear implications. If you pass five or six — your priority is scaling what works. If you pass three or four — you have real capability constrained by pilot-stage architecture. If you pass two or fewer — either the vendor is agent-washing you, or your deployment isn’t ready for the label. Either way, the path forward is the same: data readiness first, then defined outcome, then narrow scope.
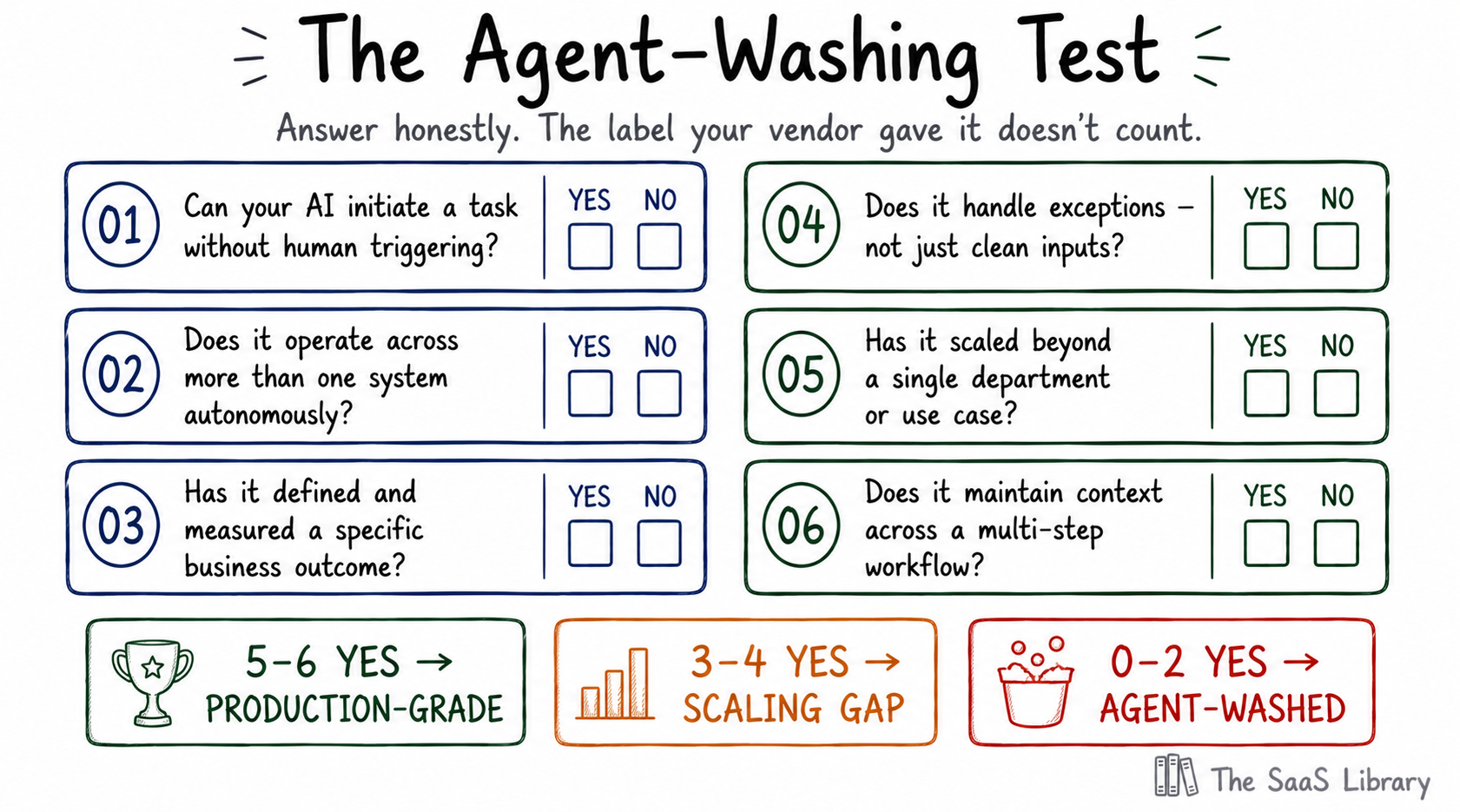
Agent-washing is the practice of marketing a chatbot, copilot, or rule-based automation as an autonomous AI agent — applying the “agentic” label to software that cannot independently plan, execute multi-step tasks, or operate across systems without human initiation at every step. Before your next vendor evaluation, run The Agent-Washing Test. If the system cannot pass question one — autonomous initiation without human triggering — the remaining five questions are irrelevant.
So What Do You Actually Do With This?
Frequently Asked Questions
Agentic AI in B2B SaaS refers to software that can autonomously plan and execute multi-step tasks without human initiation at every step — operating across multiple systems, handling exceptions, and adapting based on context. Unlike chatbots that respond to prompts or copilots that suggest actions, true agentic AI takes action independently within defined boundaries, typically across high-volume, well-defined workflows such as customer support resolution, document processing, or recruiting.
According to Sinequa’s State of Enterprise Agentic AI 2026 report (n=740 senior executives at $1B–$20B+ revenue companies), only 10% of enterprises have true agentic AI deployed at meaningful scale. While 75% claim to be adopting agentic AI (Forrester 2026) and 51% claim production deployment, only 24% have anything qualifying as genuine agent capability. McKinsey data aligns: 62% are experimenting, but fewer than 25% have scaled to production.
The three documented failure modes are data readiness (fragmented enterprise data works in pilots but breaks in production), orchestration complexity (single-agent architectures fail when multiple coordinated agents are required at scale), and undefined ROI (enterprises without specific outcome metrics rarely sustain investment past 12 months). These are organisational failures, not technology failures — which means the fix is a better decision sequence before deployment, not a better model.
A chatbot responds to prompts and waits for human input at every step. A copilot suggests actions within a human-led workflow. An agent initiates tasks without human triggering, executes multiple steps across systems, handles exceptions, and maintains context across a full workflow without re-prompting. The practical test: if a system cannot initiate a task without a human triggering it first, it is not an agent regardless of how it’s marketed.
Agent-washing is the practice of marketing a chatbot, copilot, or rule-based automation as an autonomous AI agent — applying the “agentic” label to software that cannot independently plan, execute multi-step tasks, or operate across systems without human initiation at every step. Sinequa’s 2026 enterprise survey found that 84% of enterprise leaders encounter products marketed as agents that are in reality sophisticated chatbots.