In May 2026, Google said two completely different things about llms.txt within eight days. One team called it unnecessary. Another team shipped a Lighthouse audit that checks for it. Both teams were right.
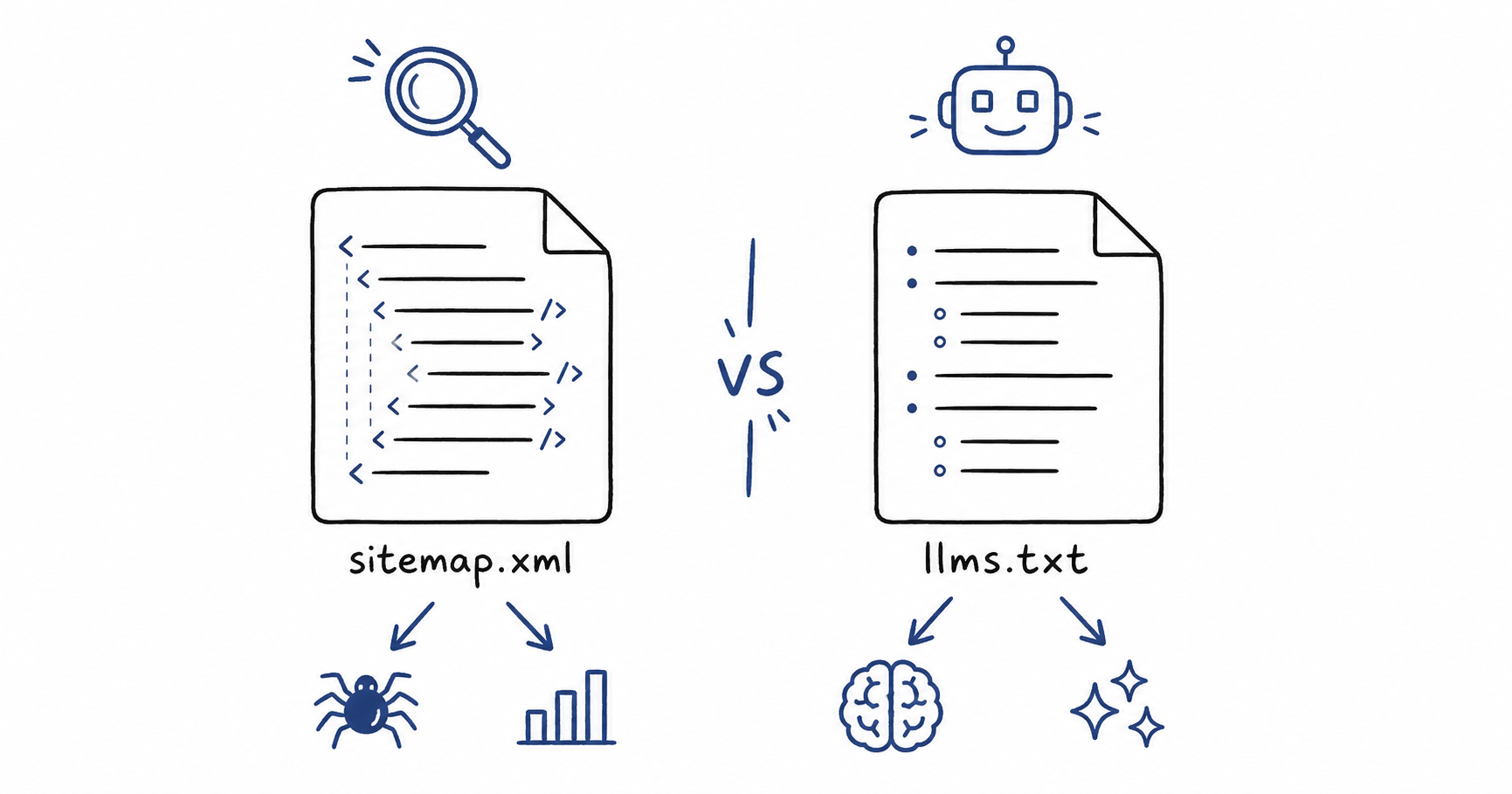
Sitemaps and llms.txt files solve different problems for different machine audiences. A sitemap is a structured XML file that helps search engines like Google index your site so human readers can find your pages. An llms.txt file is a curated Markdown document that helps AI agents understand your site when they need to fetch context, answer a question, or complete a task on a user’s behalf. In 2026, most B2B SaaS sites need a sitemap. Some will also benefit from an llms.txt file, and figuring out which combination matters is part of the broader work of optimising for AI search in 2026.
The confusion in 2026 is not that one of these files is wrong. It is that both files exist, both serve real audiences, and the audiences are visible in different layers of your traffic data: search-engine crawlers in one layer, AI agents in another. This article walks through what each file is, how we got from one to the other, and how to decide which combination your site actually needs. The framework that resolves the confusion is simple, and we call it the Two Audiences Framework.

What is a sitemap, and what is it actually for?
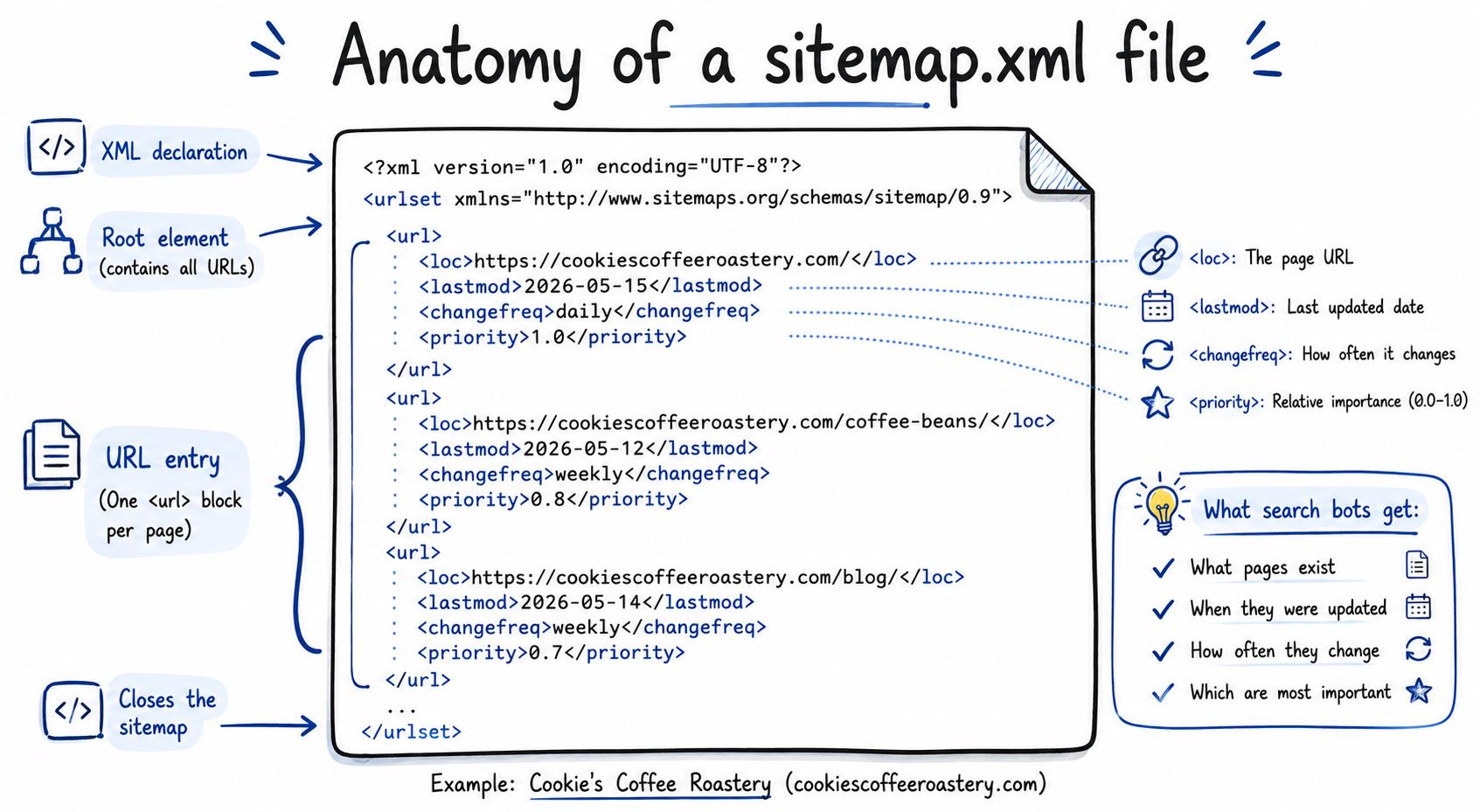
A sitemap is a structured XML file that tells search engines which pages exist on your site, when each page was last updated, and how often it changes. It is the standard machine-readable index for the open web, and almost every site on the internet has one.
The protocol was introduced by Google in June 2005 and reached broader adoption in November 2006, when Google, Yahoo, and Microsoft jointly committed to supporting Sitemap 0.9 across their search engines. That joint announcement is what turned sitemaps from a Google convention into a cross-engine standard. The reason it stuck is simple: web crawlers had no other reliable way to know what existed on a site, especially as sites grew into thousands of pages, deep navigation hierarchies, and dynamically generated URLs.
A sitemap solves three problems for a search engine. It lists pages the crawler might otherwise miss. It signals when a page was last modified, so the crawler does not waste budget re-fetching unchanged content. And it offers a relative priority signal across pages on the same site, though Google has publicly downweighted that signal in recent years.
What a sitemap is not is content. It does not describe what any page is about. It does not summarise the site. It does not help a human reader navigate. It is an index built for machines that already plan to read every page individually.
That distinction matters, because in 2024 a new kind of machine started reading sites in a fundamentally different way.
What is llms.txt, and why does it exist?
An llms.txt file is a curated Markdown document that lives at the root of a website and tells AI agents what the site is, what it offers, and which pages matter most. It is designed for systems that read content the way a colleague reads a memo, not the way a crawler indexes a database.
The proposal came from Jeremy Howard of Answer.AI on September 3, 2024. AI agents face the same problem search engines faced in the late 1990s: they need a stable way to discover a site’s high-level structure without crawling every page. A sitemap could not solve this because sitemaps describe URLs, not meaning. An llms.txt file fills that gap.
The format is intentionally simple. The file begins with an H1 for the site or product name. A blockquote summarises what the site is in one or two sentences. After that, the site owner lists pages under H2 sections, with each entry written as a bullet containing the link and a one-line description. There is an optional ## Optional section for pages that agents can deprioritise if they are running short on context.
What makes this work is that the file is curated by the site owner, not generated automatically. A sitemap aims to be exhaustive. An llms.txt file is a selection. It is what you would tell an AI agent if you had thirty seconds to explain your site.
The proposal was lightweight, the format was readable, and the file took minutes to write. That combination is why it spread.

How did we get from sitemaps to llms.txt?
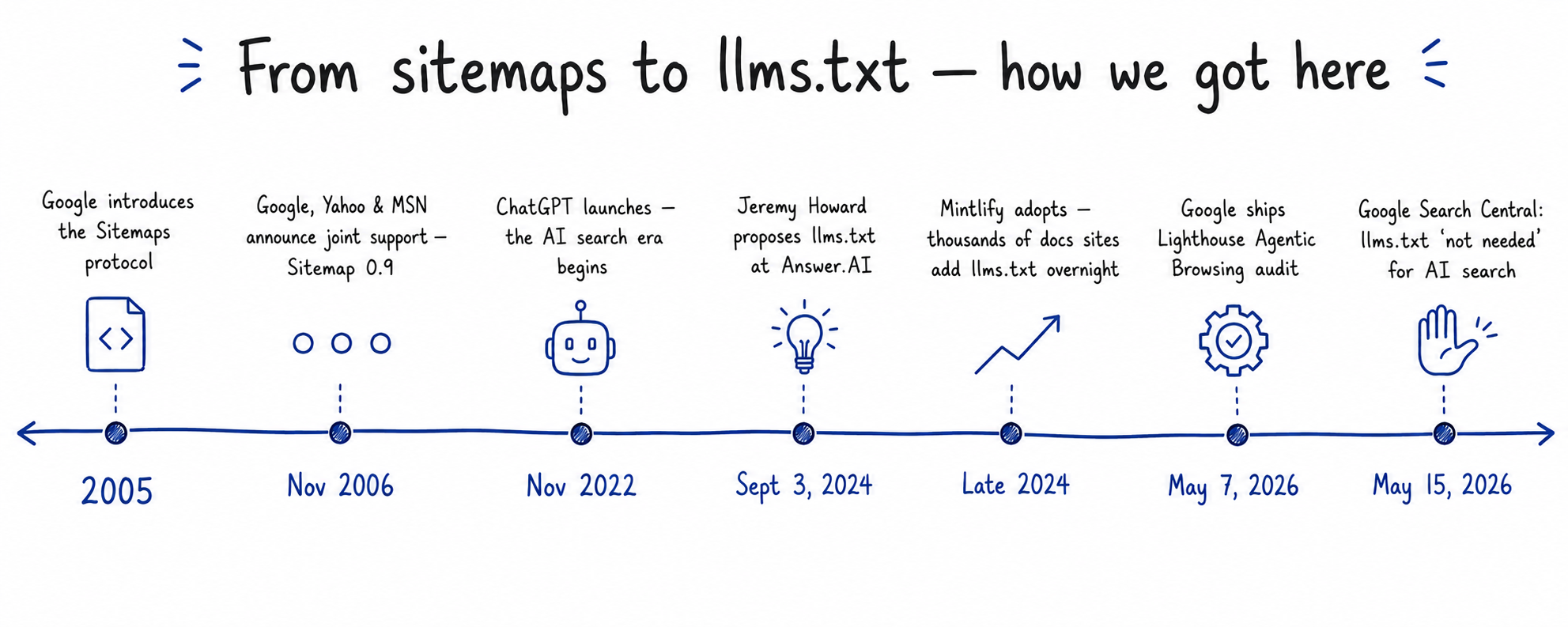
The path from sitemaps in 2005 to llms.txt in 2026 is a 21-year story told through five turning points, and each one shows the web responding to a new kind of reader.
In 2005, Google introduced the Sitemaps protocol so crawlers could index pages efficiently as the web grew faster than they could keep up. In November 2006, Google, Yahoo, and Microsoft jointly announced support for Sitemap 0.9, turning the format from a Google convention into a cross-engine standard. For the next sixteen years, sitemaps did exactly what they were designed to do.
The next turning point was not technical. In November 2022, ChatGPT launched, and within months a new kind of machine was reading the web differently. AI assistants did not crawl every page. They fetched a small number on demand and synthesised answers in real time. Sitemaps list URLs without context, and generative systems need context more than they need a list.
The proposal came on September 3, 2024. Jeremy Howard of Answer.AI published the llms.txt specification, designed for AI agents that needed to discover a site’s high-level structure quickly. By late 2024, Mintlify had added native support, and thousands of developer-tool sites shipped llms.txt files overnight.
The final two milestones, both in May 2026, came from Google itself and appeared to contradict each other. The Lighthouse team shipped an audit on May 7 that explicitly checks for an llms.txt file. Eight days later, on May 15, Google’s Search team published a generative-AI optimisation guide that told site owners they did not need one. Both statements were correct. They were just answering different questions, which is what the rest of this article is about.
How is llms.txt different from a sitemap?
The two files differ in four ways: who reads them, what they list, how they are written, and what each one is trying to accomplish.
A sitemap is read by search-engine crawlers like Googlebot and Bingbot. An llms.txt file is read by AI agents and IDE coding tools like Claude, ChatGPT, Cursor, and GitHub Copilot. These readers arrive with different intents, on different schedules, and they do different things with what they find.
A sitemap aims to be exhaustive: every page that should be discoverable goes in the file, often thousands of URLs deep. An llms.txt file aims to be selective: the site owner curates the most important pages and writes a one-line description of each, knowing the agent will only fetch a handful in a single session.
The formats reflect those goals. A sitemap is structured XML built for machines to parse at scale. An llms.txt file is Markdown that a person could read in a coffee shop. XML makes sense when the reader indexes every page anyway. Markdown makes sense when the reader needs to skim and decide.
Finally, the purpose. A sitemap answers “what pages exist on this site?” An llms.txt file answers “what is this site, and which pages should I read first?” The first is about discoverability. The second is about context. Both questions still matter in 2026, which is why neither file is replacing the other.

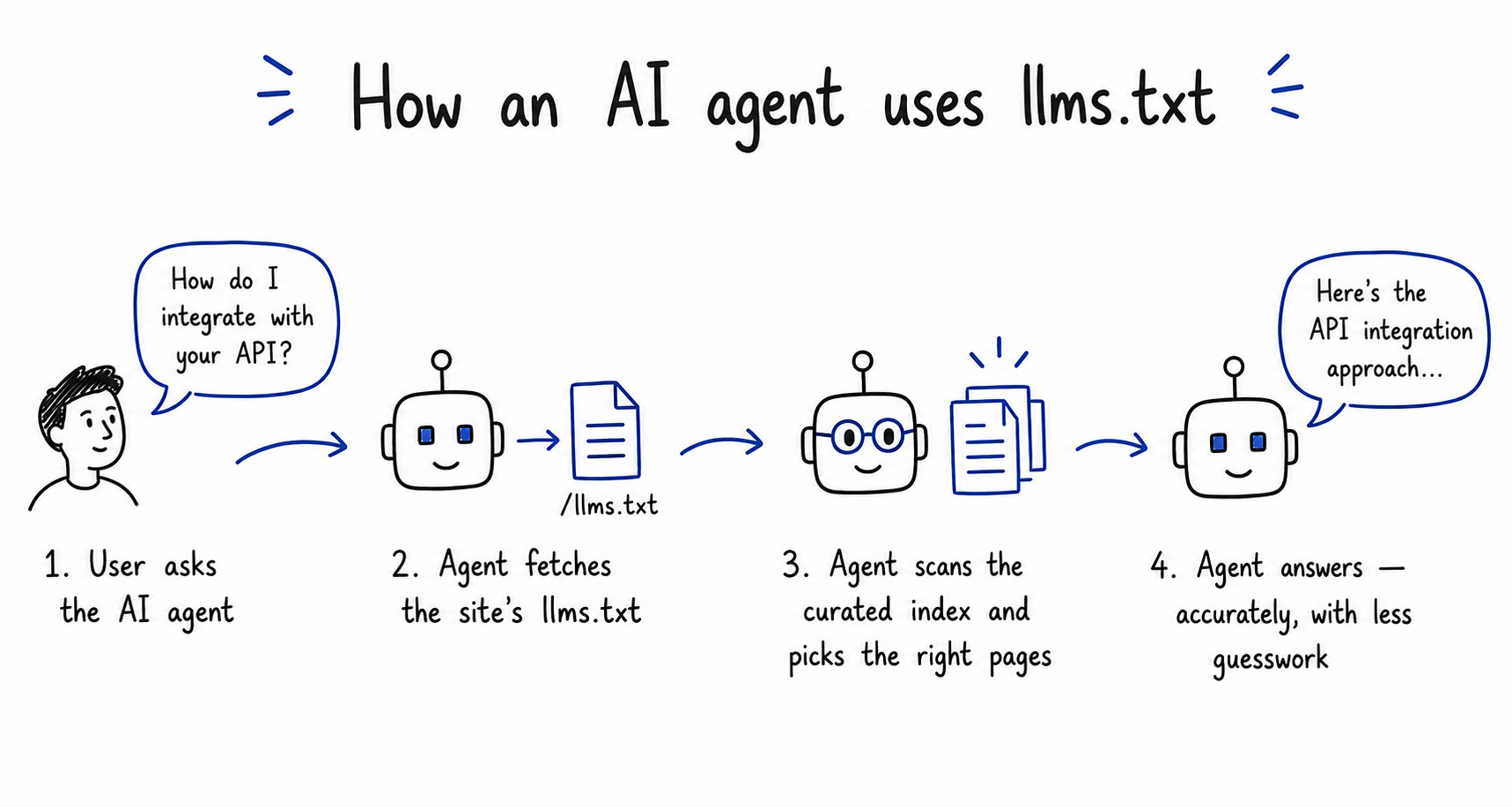
What do AI agents actually do with llms.txt?
AI agents use llms.txt as a fast index. When an agent is pointed at a website, it fetches the llms.txt file first, reads the summary and curated link list, decides which pages are relevant, and fetches only those. The file is the agent’s shortcut to figuring out a site without crawling it.
The agents that actually do this in 2026 are concentrated in one category: developer tooling. IDE coding agents like Cursor, Claude Code, GitHub Copilot, Windsurf, Cline, and Aider fetch llms.txt routinely when working with documentation sites. Anthropic’s own engineering guidance recommends documentation publishers maintain an llms.txt file precisely because Claude Code and other agents look for it. Our analysis of AI agent use cases in SaaS walks through eight more places this pattern is showing up.
The picture changes outside that category. Limy’s 2026 analysis of more than 500 million LLM bot traffic events found that only 408 directly fetched a /llms.txt file across a 90-day window. The user agents driving the citation layer, including GPTBot, ClaudeBot, PerplexityBot, and Google-Extended, almost never touched it.
The answer is that llms.txt is not built for the AI search citation layer. It is built for the agentic layer, the systems that act on a user’s behalf rather than answer a user’s question. Those systems fetch llms.txt every day. They just do not show up in the same logs the SEO community has been watching.
Does your site need an llms.txt file?
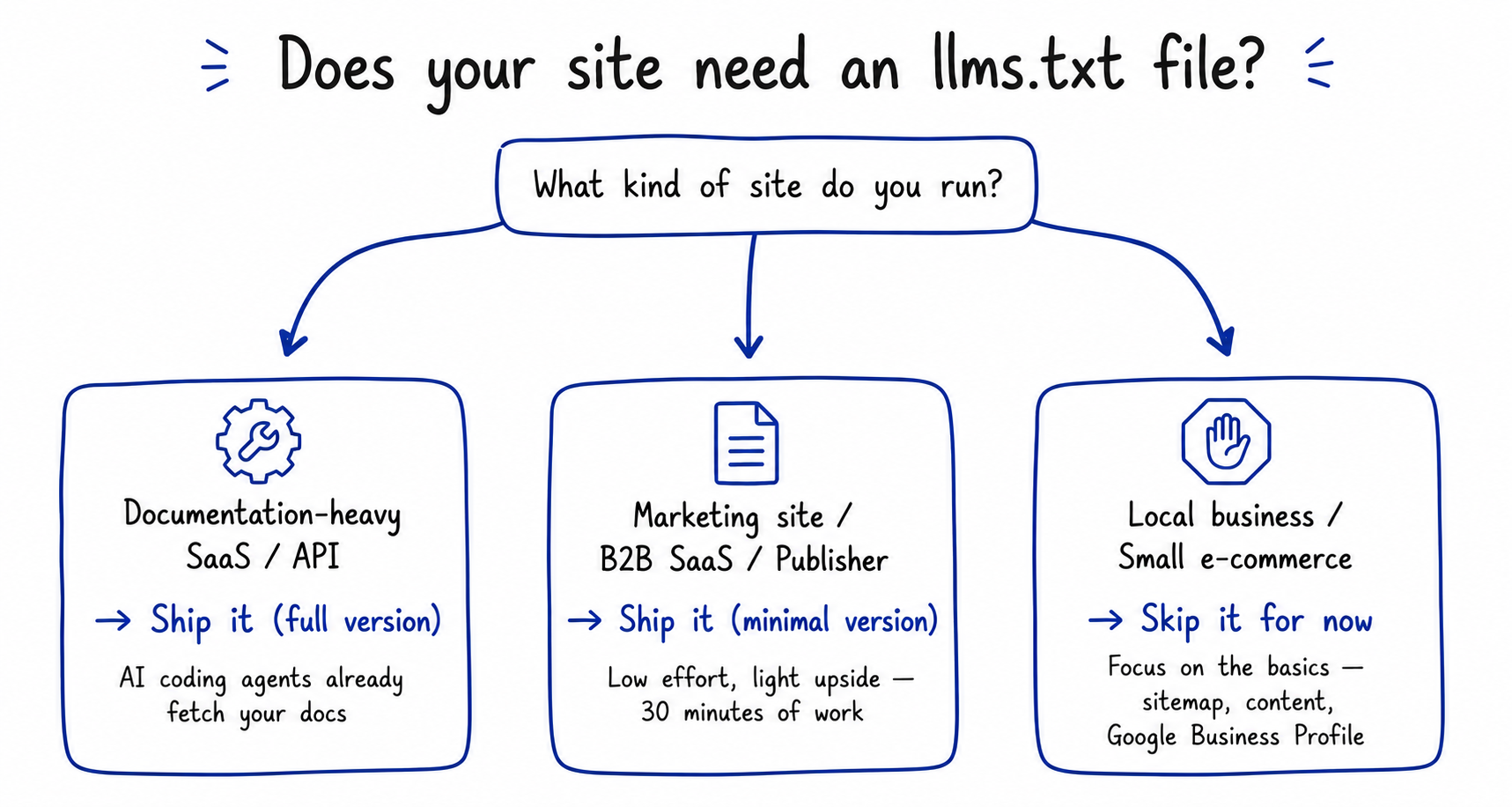
The answer depends on who is fetching your content today and how much time you have to maintain another file. There are three honest answers, and the right one depends on the kind of site you run.
If you run a documentation-heavy SaaS product, an API, or a developer tool, ship a full version. AI coding agents are already fetching your documentation, and a curated llms.txt reduces the pages they have to crawl. Anthropic publishes its own at platform.claude.com for exactly this reason.
If you run a marketing site, a B2B SaaS company, or a publication, ship a minimal version. List your top fifteen to twenty pages with one-line descriptions and stop. Thirty minutes of work for a clean signal to any agent that fetches it, with no measurable downside.
If you run a local business or a small e-commerce store, skip it for now. The audiences you care about are search engines and humans, and llms.txt does not help with either. Focus on the basics: a working sitemap, fast pages, clean content, and a complete Google Business Profile.
The counter-evidence is worth naming honestly. SE Ranking analysed 300,000 domains in 2026 and found around 10% had published an llms.txt file, with no statistically significant correlation between having one and being cited by AI search systems. That finding is real, but it measures the wrong layer. It measures AI search citation, not the agentic layer the file is built for.
How do you create an llms.txt file?
You write an llms.txt file the same way you would write a one-page brief for a colleague joining your team. Open a plain text editor, name the file llms.txt, and save it at the root of your domain at yoursite.com/llms.txt. The official specification at llmstxt.org documents the format in full.
The file begins with an H1 containing your brand or product name. Below it, a blockquote summarises what your site is in one or two sentences. This summary is the most important piece of content in the file because it is the first thing an AI agent reads.
After the summary, group your links under Markdown H2 headings. Each link is a bullet in the format - [Page Title](URL): one-line description. A bullet that says “About” gives an agent nothing; “About: founded in 2019, family-run roastery in Portland, Oregon” gives an agent a usable signal. Keep descriptions to one line.
An optional final ## Optional section lists pages that agents can deprioritise if they are running short on context. Press kits, career listings, partner programs.
For hosting, the file lives at the root of your domain. On WordPress, the easiest path is a plugin that writes the file and keeps it updated as you publish, though many publishers prefer to maintain a hand-curated version for editorial discipline. AI agents discover the file by fetching /llms.txt directly, with no submission step required. The broader question of how llms.txt fits into a 2026 strategy across SEO, AEO, and GEO is covered in our piece on hybrid engine optimisation.
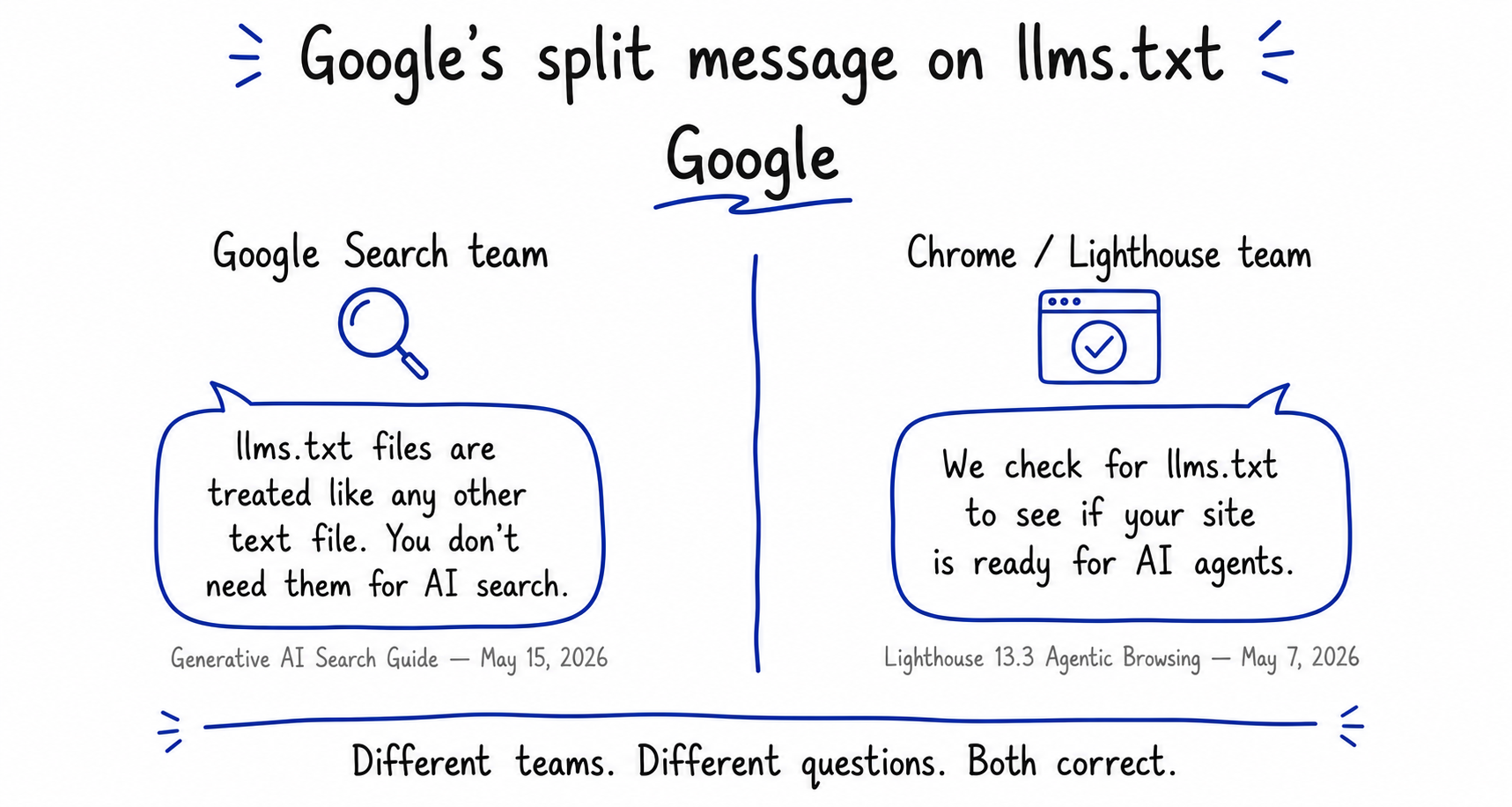
What does Google actually say about all this?
Google’s official position is that you do not need llms.txt for AI search. On May 15, 2026, Google Search Central published a generative-AI optimisation guide grouping llms.txt with content chunking and AI-specific rewriting as tactics that do not help with AI Overviews or AI Mode. The exact wording: “llms.txt files: Google’s crawler may discover these files, but they’re treated like any other text file.” John Mueller, Google’s Search Advocate, has compared llms.txt to the deprecated keywords meta tag, noting that server logs show AI search bots do not request the file.
Eight days earlier, on May 7, 2026, a different Google team shipped a Lighthouse audit that does the opposite. The Lighthouse 13.3 release added an Agentic Browsing audit category, and one check verifies whether your site provides an llms.txt file. The Lighthouse documentation describes the file as “a machine-readable summary of a website’s content, specifically designed for LLMs and AI agents.”
Both positions are correct. The Search team is answering “does llms.txt help my site appear in AI Overviews?” and the answer is no. The Lighthouse team is answering “is your site ready for AI agents that act on a user’s behalf?” and the answer is yes. The two teams are not contradicting each other; they are answering different questions, and no single Google document explains how they relate.
For most B2B SaaS sites, both answers matter. If you only care about AI search visibility, the Search team’s guidance applies, and our breakdown of Google’s AI search guide covers that position in full. If you care about agentic readiness, the Lighthouse team’s guidance applies, and an llms.txt file is the cheapest signal you can ship. A strong AEO foundation sits underneath both answers.
The reason llms.txt feels confusing in 2026 is that the SEO community has been watching the wrong logs. AI search citation bots like GPTBot and ClaudeBot rarely fetch the file. IDE coding agents like Cursor, Claude Code, and GitHub Copilot fetch it constantly. The file is doing real work in one layer of the web while being invisible in another, and your decision about whether to publish one depends entirely on which layer your audience lives in.
Sitemaps are written for search-indexing bots that catalog a site for human readers. llms.txt files are written for AI agents that fetch context to act on a user’s behalf. The two audiences need different files because they do different jobs. For most B2B SaaS sites in 2026, a sitemap is non-negotiable and an llms.txt file is a low-cost addition that helps the agentic layer find your content faster. Skip llms.txt only if no AI agents touch your traffic today and you have no documentation worth indexing.
Frequently Asked Questions
llms.txt is a curated Markdown file placed at the root of a website (yoursite.com/llms.txt) that helps AI agents understand a site’s content, structure, and most important pages. The file was proposed by Jeremy Howard of Answer.AI in September 2024. It is read by AI agents and IDE coding tools like Cursor, Claude Code, and GitHub Copilot, not by search engines.
Most B2B SaaS sites should have both. A sitemap helps search engines index your pages for human readers, and an llms.txt file helps AI agents fetch context to act on a user’s behalf. The two files serve different machine audiences. Sitemaps are non-negotiable. llms.txt is optional but low-cost, and recommended for documentation-heavy sites and SaaS companies.
Google’s Search team published official guidance on May 15, 2026, stating that llms.txt is not needed for Google’s AI Overviews or AI Mode. The Lighthouse team shipped an Agentic Browsing audit on May 7, 2026, that checks whether a site provides the file. Both positions are correct. They answer different questions about your site’s machine-readability.
Open a plain text editor, name the file llms.txt, and save it at the root of your domain. Start with an H1 containing your brand name, add a one-or-two-sentence blockquote summary, then list your important pages under H2 sections with bullet links in the format – [Page Title](URL): description. Upload to your site root and the file is live.
The Two Audiences Framework is a model for understanding modern site machine-readability: sitemaps are written for search-indexing bots that catalog a site for human readers, while llms.txt files are written for AI agents that fetch context to act on a user’s behalf. The two audiences need different files because they do different jobs.