Most models the enterprise AI market calls “open source” are not open source. The label is marketing — and B2B buyers are making infrastructure decisions on the strength of it.
The AI industry has a language problem. It calls things “open source” that are not open source — and it has been doing it long enough that most buyers have stopped questioning the label.
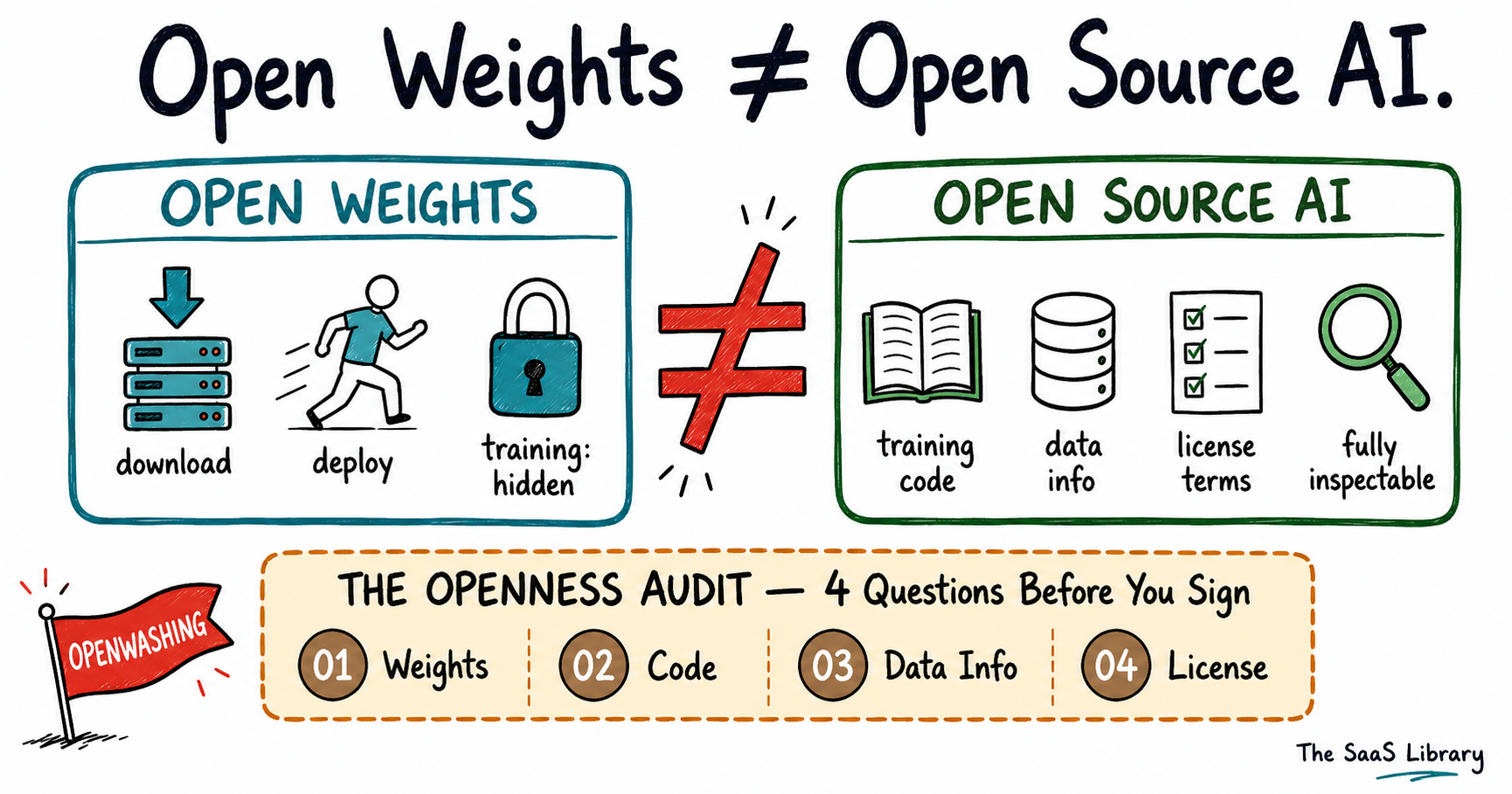
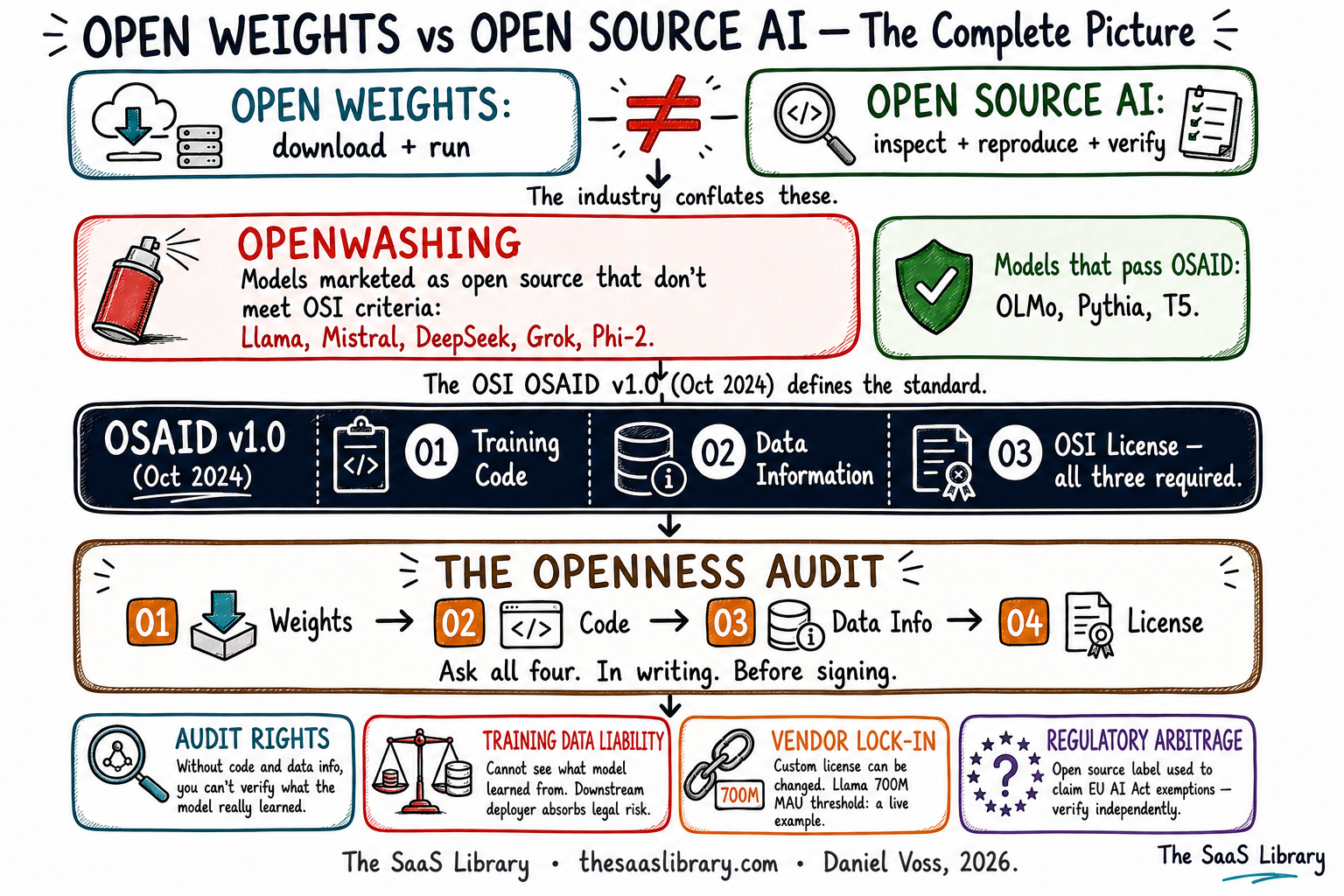
Open weights and open source are not synonyms. They never were. One means you can download and run a model. The other means you can inspect, reproduce, and verify everything that went into building it. The gap between those two things is where vendor risk lives — and where B2B buyers are making infrastructure decisions on false assumptions.
This article names the deception, explains what the difference actually means, and gives you a framework for evaluating what any AI vendor means when they use the word “open.”
What is the difference between open weights and open source AI?
Open weights and open source AI are two different things that the industry treats as one. Open weights means a company has released the trained model parameters — you can download, run, and fine-tune the model. Open source AI, under the OSI’s OSAID v1.0, additionally requires full training code, data information sufficient to reproduce the system, and parameters released under an OSI-approved license.
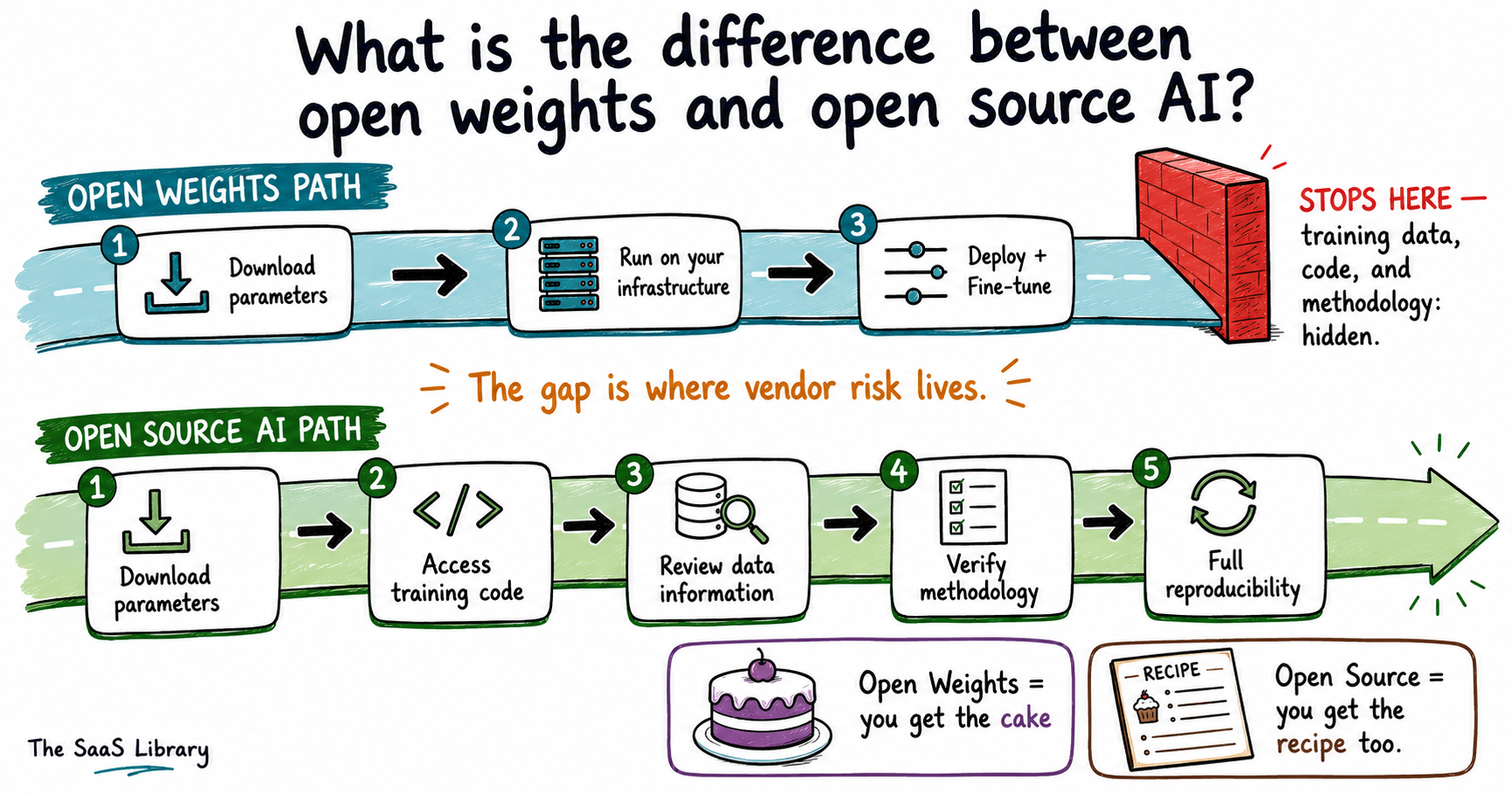
Open weights means a company has released the trained parameters of a model. You can download those parameters, run the model on your own infrastructure, fine-tune it for your use case, and integrate it into your products. What you cannot do is see how those parameters were produced. The training data, the data processing pipeline, the training code, the architectural decisions made along the way — none of that is required to be disclosed. You are getting the finished product. You are not getting the recipe.
Open source AI, by the formal definition established by the Open Source Initiative in October 2024, requires something categorically different. Under the OSI’s Open Source AI Definition (OSAID v1.0), a model qualifies as open source only if it provides three things: complete training and inference code under an OSI-approved license, sufficiently detailed data information so that a skilled person could reproduce the system from scratch, and the model parameters themselves under OSI-approved terms. The four freedoms that must be guaranteed are the freedom to use, study, modify, and share — for any purpose, without asking permission.
The practical gap is enormous. An open weights model lets you consume intelligence. An open source model lets you verify it.
Think of it this way. Open weights is like being handed a calculator. You can use it, you trust it works, but you have no idea what is happening inside the chip. Open source is like being handed the circuit diagram, the component list, and the assembly manual alongside the calculator. You can build a copy. You can find the flaw. You can prove to your auditor exactly what it does.
For a developer building a side project, this distinction barely matters. For a B2B company deploying AI into customer-facing workflows, regulated data environments, or security-sensitive infrastructure, it is the difference between a tool you can audit and one you have to trust blindly.
This distinction is the foundation of everything that follows. Every claim an AI vendor makes about openness — and every risk you carry when you deploy their model — depends on which side of this line their product actually sits on.
Why do AI companies call their models “open source” when they are not?
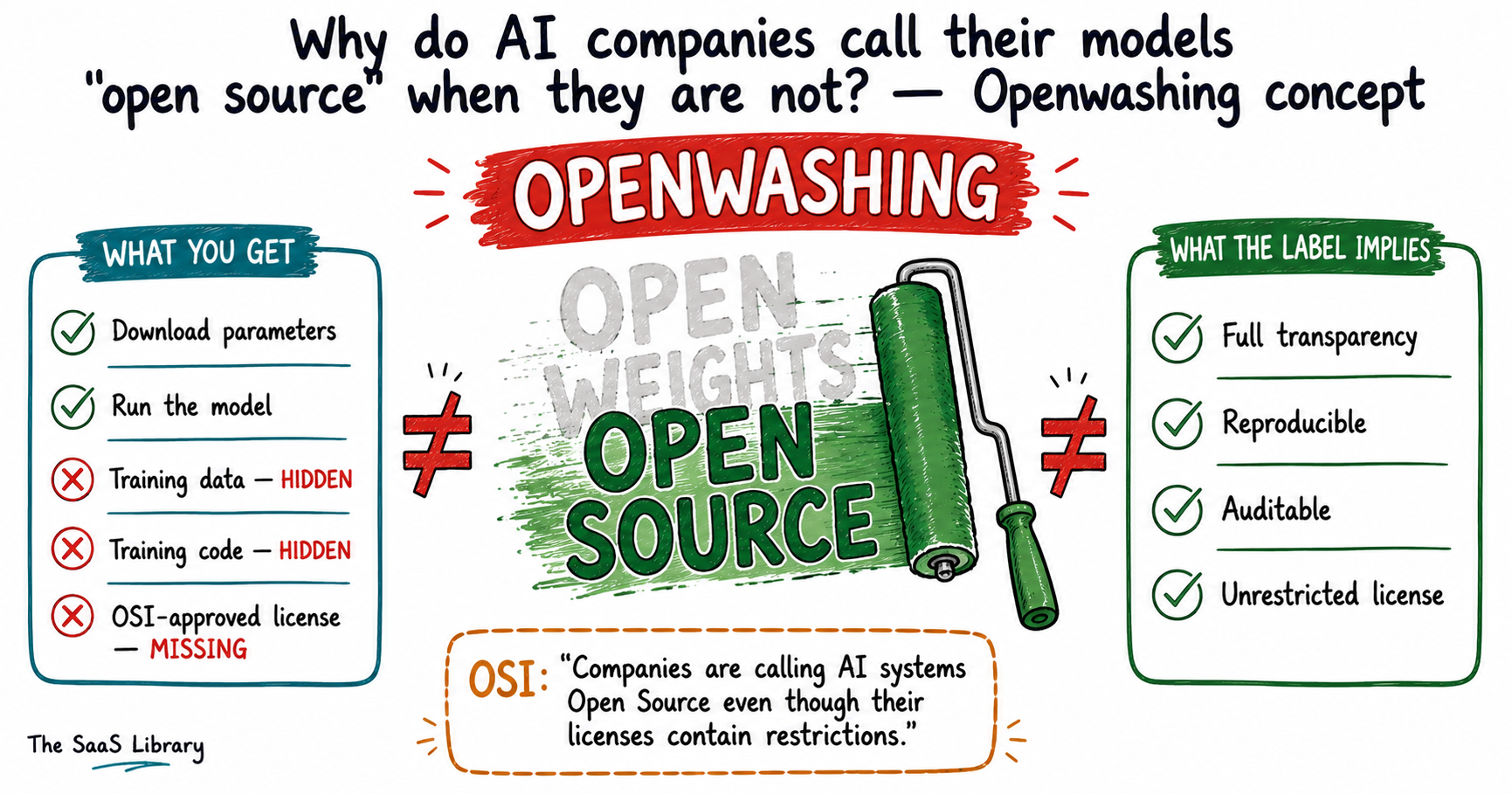
AI companies call their models “open source” because the label is worth hundreds of millions of dollars in adoption, trust, and regulatory goodwill — whether it is accurate or not. It signals transparency, auditability, and freedom from vendor lock-in. Claiming that label drives enterprise deals, attracts developers, and shapes how regulators treat the product. Accuracy is a secondary concern.
This practice has a name. The OSI calls it openwashing: releasing one component of an AI system — typically just the weights — while claiming the full “open source” designation. It is the AI equivalent of a food brand printing “natural” on a product with no legally defined natural ingredients. The label is chosen for its marketing value, not its accuracy.
Meta is the clearest example of openwashing at scale. Llama has been downloaded over one billion times as of March 2025, according to Meta, making it the most widely deployed model marketed under the open source label. Meta has not disclosed the training data used to build Llama. The license is a custom document — not any OSI-approved license — and it contains restrictions no genuine open source license permits: companies with more than 700 million monthly active users must negotiate a separate commercial agreement with Meta, and using Llama outputs to train competing models is prohibited. OSI validated Llama 2 against the OSAID criteria. It did not pass.
Meta is not alone in this. OSI’s validation exercise found that Grok (xAI), Phi-2 (Microsoft), and Mixtral (Mistral) also failed to meet OSAID criteria. Each is widely described as “open source” in vendor marketing, press coverage, and analyst reports. The broader pattern of trust erosion in B2B SaaS is reinforced every time a label misleads a buyer.
A structural regulatory incentive compounds the problem. The EU AI Act grants special treatment to “free and open source” AI systems, exempting them from several documentation and compliance obligations that would otherwise apply. A model that successfully claims the open source label — even loosely — potentially sidesteps those requirements. The incentive to use the term broadly is built into the regulatory architecture itself.
The Open Source Initiative states the problem plainly on its own website: “Companies are calling AI systems ‘Open Source’ even though their licenses contain restrictions that go against the accepted principles and freedoms of Open Source.” The OSI has no enforcement mechanism to compel compliance. What it can do is make the standard public and unambiguous — which the OSAID now does.
Stefano Maffulli, Executive Director of the Open Source Initiative, spelled out the intended correction at the OSAID launch: “Our hope is that when someone tries to abuse the term, the AI community will say, ‘We don’t recognize this as open source,’ and it gets corrected,” he told TechCrunch. That correction has not happened at scale yet. This article is one attempt to accelerate it.
Evaluating an AI vendor right now? The Openness Audit gives you four questions to ask in writing before any contract is signed.
Jump to the Framework →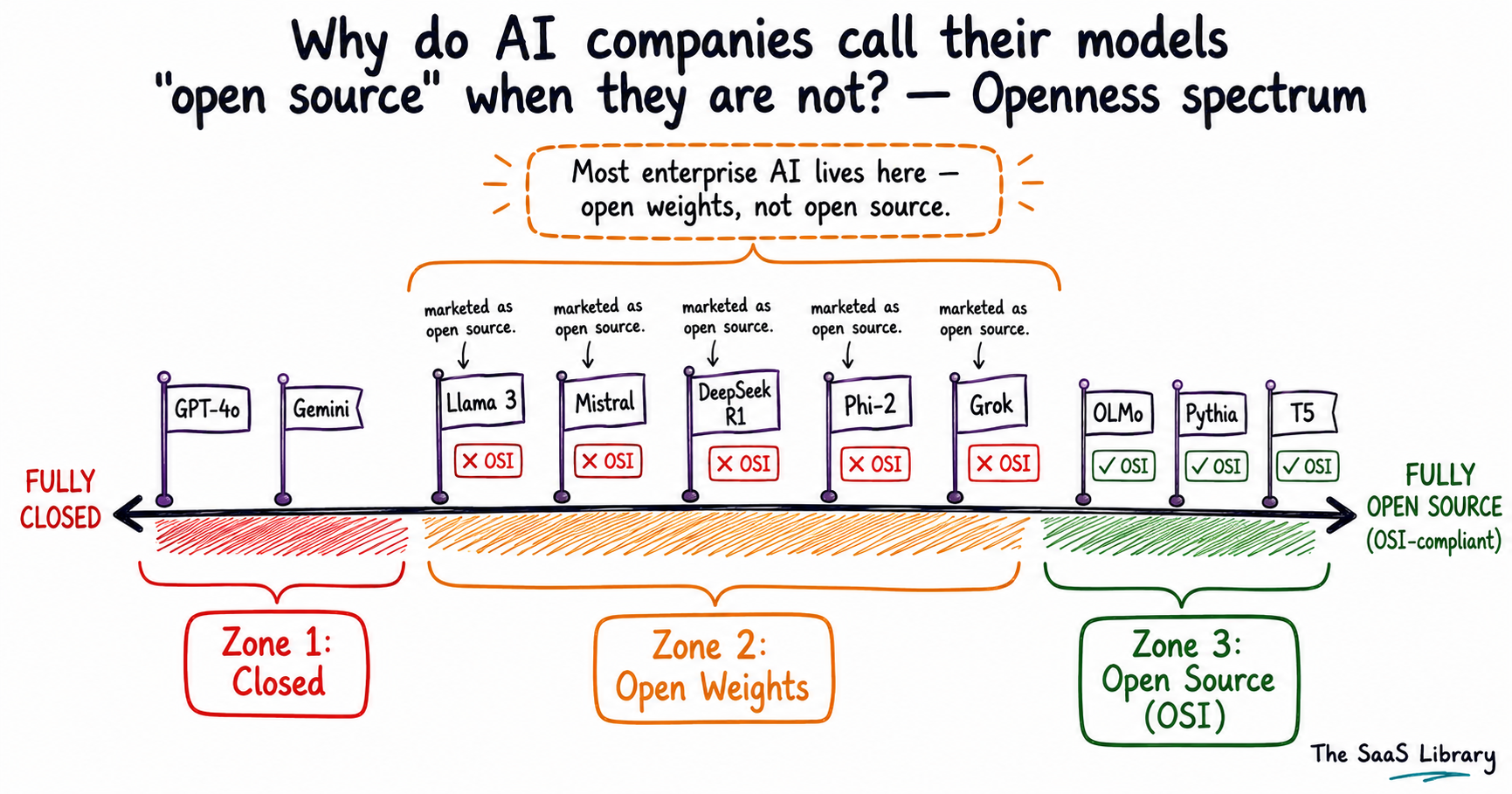
Most enterprise AI adoption is clustered in Zone 2 of this spectrum — open weights models that are freely downloadable and extremely useful, but not transparently reproducible or verifiable. Understanding which zone a vendor’s model occupies is the starting point for any serious AI procurement conversation.
What does the OSI’s open source AI definition actually require?
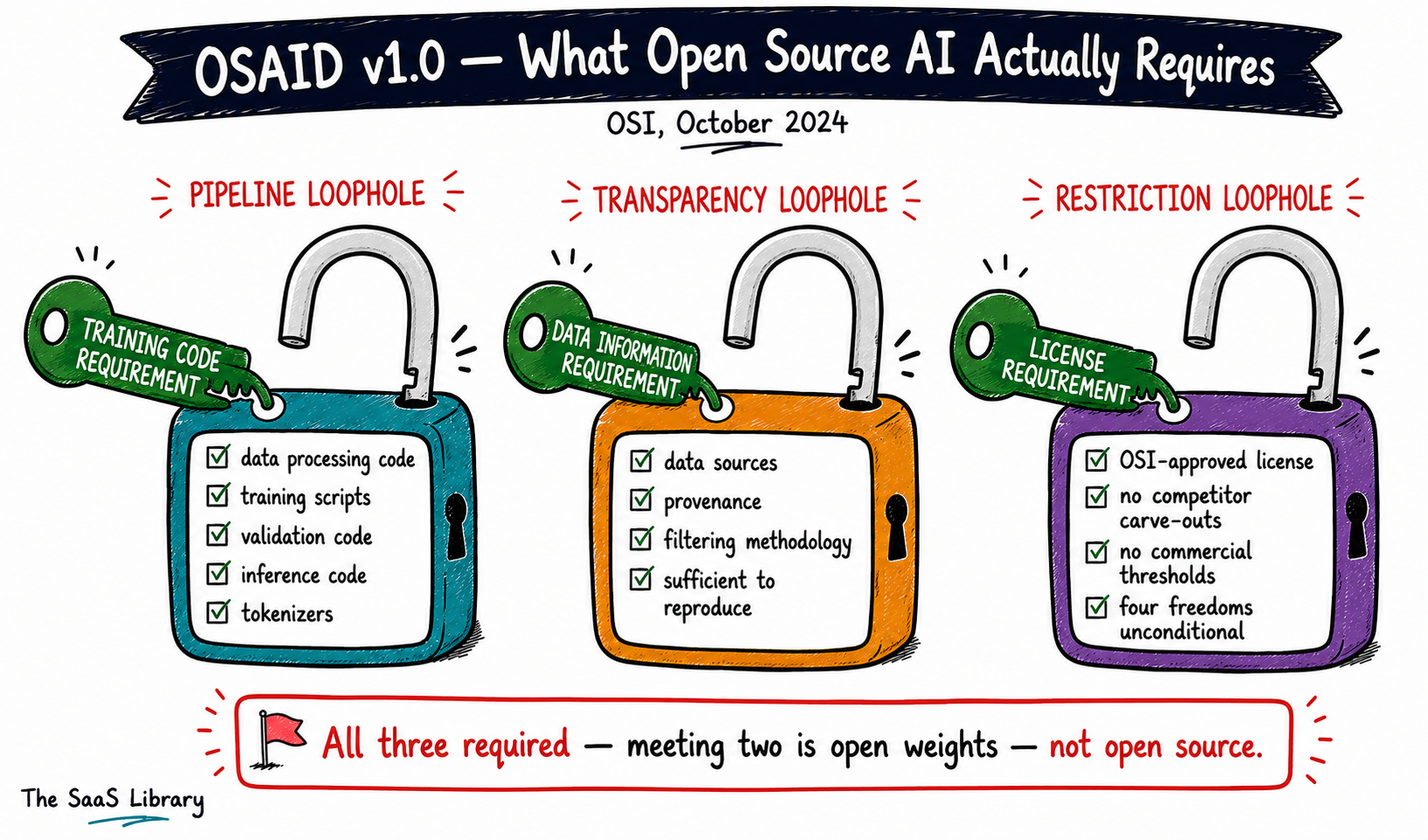
The OSI’s open source AI definition requires three things: complete training and inference code under an OSI-approved license, sufficiently detailed data information so a skilled person can reproduce the system, and the model parameters under OSI-approved terms. Published as OSAID v1.0 on October 28, 2024, after two years of development with over 25 organisations including Microsoft, Google, Amazon, Meta, Mozilla, and the Linux Foundation, it is the first formal standard defining what open source means in the context of AI.
Each of the three requirements closes a specific loophole that openwashing exploits.
The code requirement closes the pipeline loophole
Full training and inference code must be released — not just the model card or a high-level architecture description. This includes data processing and filtering code, training scripts with arguments and settings, validation and testing code, tokenisers, and inference code. A company that releases weights but withholds the training pipeline has not met this requirement.
The data information requirement closes the transparency loophole
The OSAID does not require companies to release the full training dataset — that would be unworkable given copyright, privacy, and competitive constraints on most large datasets. What it does require is a sufficiently detailed description: the complete list of data sources, how data was obtained, how it was filtered and processed, and enough detail that a skilled practitioner could build a substantially equivalent system. A company that says “trained on publicly available internet data” has not met this requirement.
The license requirement closes the restriction loophole
Model parameters must be released under OSI-approved terms — not a custom community license with carve-outs for competitors or commercial thresholds. The four freedoms must be unconditional: use for any purpose, study, modify, and share, without having to ask permission. A license that prohibits use by companies above a certain size, or that bans using outputs to train competing models, fails this requirement by definition.
The models OSI assessed — finding Pythia, OLMo, Amber, CrystalCoder, and T5 passing, and Llama 2, Grok, Phi-2, and Mixtral failing — were part of a definitional exercise, not a certification programme. OSI notes these results are a learning moment, not a formal stamp of approval. The list is the most authoritative public benchmark available — but it is not a certification. See also how these dynamics play out in the AI model transparency debate.
So far we have covered what open source AI actually requires and why the industry ignores that definition. Now the more useful question: which specific models pass, which ones fail, and what that means when one of them appears in your next vendor pitch.
Which AI models are actually open source — and which ones are not?
Very few AI models in active commercial use are genuinely open source by the OSI’s definition. OSI’s validation exercise identified five models that pass OSAID criteria: Pythia (EleutherAI), OLMo (AI2), Amber and CrystalCoder (LLM360), and T5 (Google). None of these are the models B2B buyers encounter most frequently in vendor pitches, AI procurement conversations, or infrastructure evaluations.
The models B2B buyers encounter most frequently are open weights, not open source. The table below maps the most commonly deployed models against the four OSAID axes — weights, training code, data information, and license terms — using publicly available documentation and OSI’s own validation output.
| Model | Weights | Training Code | Data Info | OSI License | OSAID Status |
|---|---|---|---|---|---|
| OLMo (AI2) | ✓ | ✓ | ✓ | ✓ | Passes |
| Pythia (EleutherAI) | ✓ | ✓ | ✓ | ✓ | Passes |
| T5 (Google) | ✓ | ✓ | ✓ | ✓ | Passes |
| Llama 2 (Meta) | ✓ | ✗ | ✗ | ✗ | Fails |
| Llama 3.x (Meta) | ✓ | ✗ | ✗ | ✗ | Fails* |
| Mistral / Mixtral | ✓ | ✗ | ✗ | ✗ | Fails |
| Phi-2 (Microsoft) | ✓ | ✗ | ✗ | ✗ | Fails |
| Grok (xAI) | ✓ | ✗ | ✗ | ✗ | Fails |
| DeepSeek R1 | ✓ | ✗ | ✗ | ✗ | Fails* |
* Llama 3.x and DeepSeek R1 were not included in OSI’s formal validation exercise. Assessed against the same OSAID criteria using publicly available license documentation. Source: OSI validation, opensource.org/ai, 2024.
One clarification on the Llama entries is necessary. OSI formally validated Llama 2 and found it failing. Llama 3 and later versions were not part of OSI’s validation exercise, but use a custom community license that remains outside OSI-approved terms and withholds training data — placing it in the same category by the same criteria.
DeepSeek R1 deserves specific attention because it arrived with significant “open source” marketing in early 2025. DeepSeek released the model weights and published a technical report describing the architecture. It did not release full training code, did not disclose training data in sufficient detail under OSAID criteria, and its license is not OSI-approved. It is open weights. The technical report is valuable. The “open source” label is not accurate.
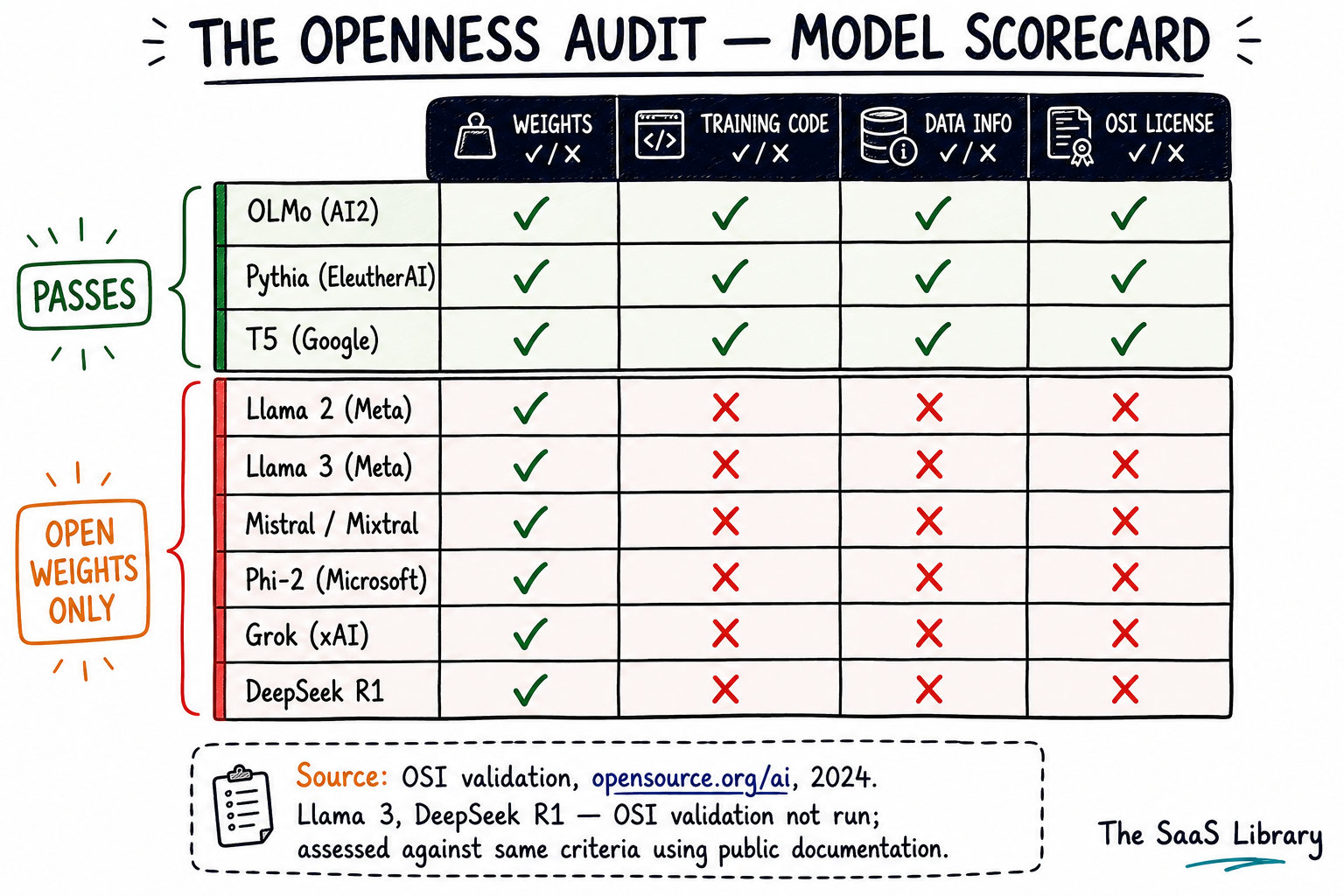
The practical implication for B2B buyers: every model currently driving enterprise AI adoption at scale — Llama, Mistral, DeepSeek — is open weights only. The models that pass the OSI definition are primarily research-oriented and not the ones appearing in vendor procurement conversations. Buyers evaluating AI vendors should assume “open source” means “open weights” until proven otherwise by all four axes of the Openness Audit.
The Openness Audit: how B2B buyers should evaluate any AI vendor’s openness claim
B2B buyers should evaluate AI vendor openness claims by running four questions against any model before procurement — one for each axis the OSI’s definition requires. The Openness Audit is a structured due diligence framework that converts the open weights vs open source distinction into a procurement-ready checklist. It does not require legal expertise or technical deep-dives. It requires four questions, asked in writing, before signing anything.
The four axes are Weights, Code, Data Information, and License Terms. A vendor claiming “open source” must pass all four. Passing three is not open source — it is open weights with good documentation.
Axis 1 — Weights: Can we download and self-host the model parameters?
A yes here is the minimum bar — and the only bar most vendors clear. Downloadable weights mean you can run the model on your own infrastructure, fine-tune it for your use case, and avoid API dependency. This matters for latency, cost, and data privacy. It does not mean you can audit the model, reproduce it, or verify what it learned and from what.
Axis 2 — Code: Is the full training and inference pipeline publicly available under an OSI-approved license?
A yes here means you can inspect how the model was built — not just how it runs. Full training code includes data processing scripts, training arguments and hyperparameters, validation and testing pipelines, and inference code. If a vendor points to a GitHub repository containing only inference code or a model card, that is not a yes. Ask specifically: is the complete training pipeline open under an OSI-approved license such as Apache 2.0 or MIT?
Axis 3 — Data Information: Is there sufficient documentation of the training data to reproduce the system?
A yes here means the vendor has disclosed what data the model was trained on, where it came from, how it was filtered, and what was excluded — in enough detail that a skilled practitioner could build a substantially equivalent system. A model card that says “trained on a diverse mix of internet data and licensed datasets” is not a yes. This axis is where almost every commercial model fails, because training data is the primary source of competitive advantage and legal liability simultaneously.
Axis 4 — License Terms: Are the weights and code released under OSI-approved terms with no use restrictions?
A yes here means the license grants the four freedoms unconditionally — use for any purpose, study, modify, share — with no carve-outs for competitors, no commercial thresholds, no prohibited use categories beyond what OSI-approved licenses permit. A custom community license is not a yes. An acceptable use policy attached to the weights is not a yes. Ask your legal team to confirm the license identifier before deployment.
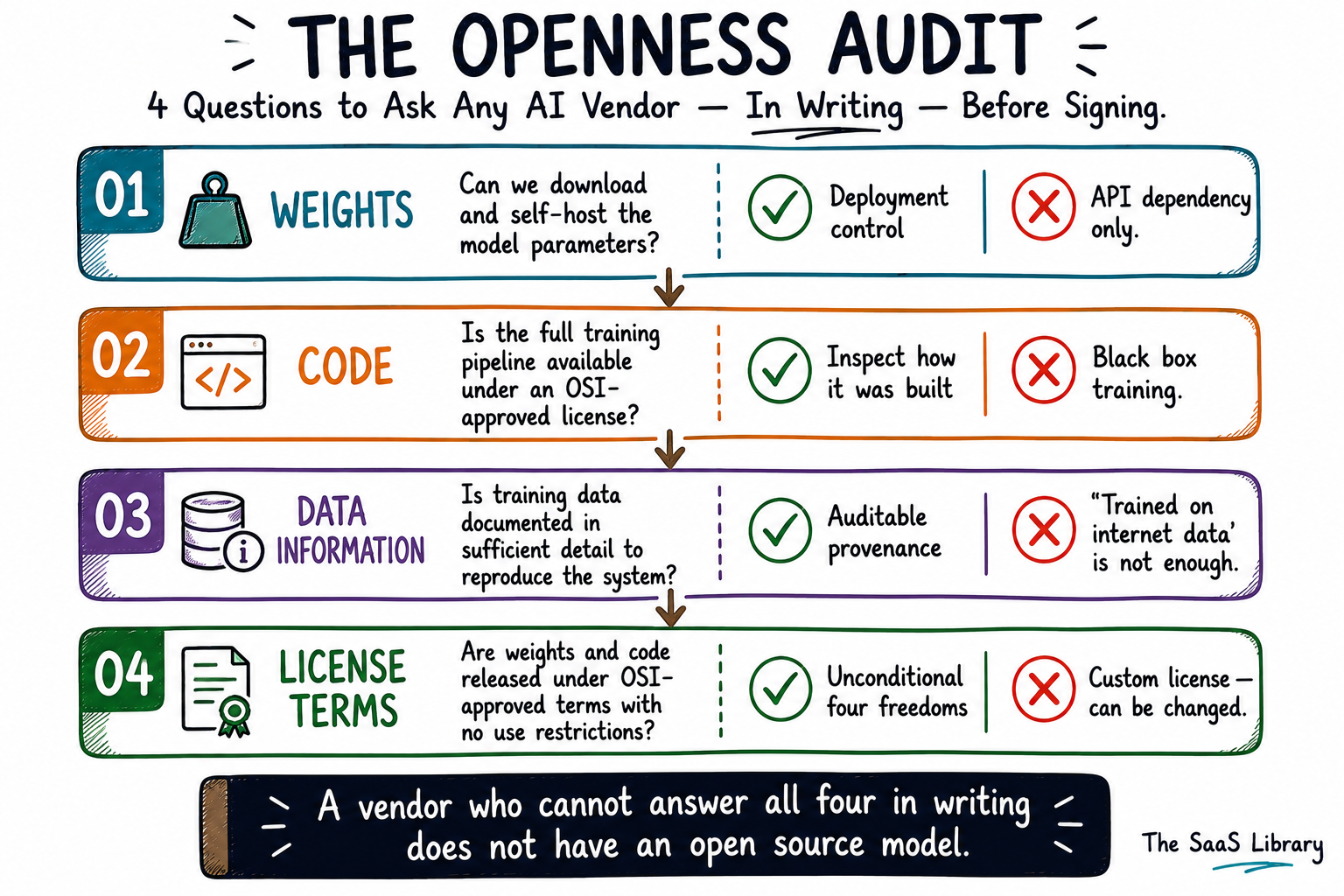
The Openness Audit does not tell you which model to deploy — it tells you what a vendor’s openness claim actually means. A model can fail three of four axes and still be the right infrastructure choice. What it cannot be is an open source model. That distinction belongs in your procurement record. Read how enterprise AI compliance risk compounds when vendors misuse the label — The Governance Readiness Gap →
What does an AI model’s openness level mean for your compliance and vendor risk?
An AI model’s openness level determines three things that matter directly to B2B compliance and vendor risk: your ability to audit what the model does, your exposure if the model causes harm, and your exit options if the vendor changes terms. Open weights gives you deployment control. Open source gives you verification rights. The gap between those two things maps directly onto categories of enterprise risk that procurement teams, legal counsel, and CISOs are already responsible for.
Audit rights are the first risk category
Regulated industries — financial services, healthcare, legal, government — are increasingly required to explain AI-assisted decisions. A model you cannot inspect is a model you cannot explain. Open weights lets you observe outputs. Open source lets you trace outputs back to training decisions, data sources, and architectural choices. If your compliance framework requires explainability at the model level, open weights alone does not satisfy it. The question to ask your vendor is not “is your model open source?” — it is “can we audit the training pipeline if a regulator asks us to?” Read how this risk compounds in practice in The Governance Readiness Gap.
Training data liability is the second risk category
A model trained on data it had no right to use exposes every downstream deployer to legal risk. Copyright litigation against AI training data is active across multiple jurisdictions as of mid-2026. Open weights gives you no visibility into what the model learned from. Open source — specifically the data information requirement — gives you enough documentation to assess whether the training data creates liability for your use case. If a vendor cannot tell you what their model was trained on in sufficient detail, that is not a transparency gap. It is a legal exposure you are absorbing on their behalf. This connects directly to the concerns raised in our coverage of shadow AI risk in SaaS stacks.
Vendor lock-in is the third risk category
Open weights with a restrictive custom license creates a dependency that looks like freedom but is not. Meta’s 700 million MAU commercial threshold is a live example: a B2B SaaS platform that builds on Llama and scales into enterprise deployments could cross that threshold and find itself renegotiating terms from a position of deep technical dependency. An OSI-approved license eliminates that category of risk entirely — the freedoms are unconditional and cannot be revoked. A custom license can be changed. An Apache 2.0 license cannot be taken back.
An OSI-approved license such as Apache 2.0 or MIT cannot be retroactively revoked — the freedoms granted apply permanently to the version released under those terms. A custom license can be changed unilaterally by the vendor at any time. This distinction is the difference between a freedom and a permission.
Regulatory arbitrage is the fourth risk category
When a vendor markets a model as open source to qualify for EU AI Act exemptions, and that model does not meet OSI criteria, the vendor is potentially misrepresenting the model’s regulatory status. The evidence suggests that organisations deploying that model and citing the open source exemption in their own compliance documentation risk inheriting that misrepresentation. B2B buyers in EU-regulated markets should verify independently whether a deployed model meets the EU AI Act’s open source criteria — which does not require OSI compliance but does require specific transparency conditions — rather than relying on vendor claims in compliance filings. The scale of this risk is documented in our analysis of the AI governance gap facing enterprise teams.

The Openness Audit exists precisely because these risks are not visible in a vendor pitch deck. They surface in procurement, in legal review, and — when things go wrong — in regulatory investigations. Running four questions before signing a contract is the cheapest form of AI vendor due diligence available. For context on how these risks interact with broader B2B SaaS infrastructure trends in 2026, the pattern is consistent: the vendors moving fastest are the ones most aggressively using the open source label.
Frequently asked questions about open weights vs open source AI
What is the difference between open weights and open source AI?
Open weights AI means the trained model parameters are publicly available for download and deployment — you can run the model, fine-tune it, and self-host it. Open source AI, under the OSI’s OSAID v1.0, requires three additional components: complete training and inference code under an OSI-approved license, sufficiently detailed training data information to reproduce the system, and model parameters under OSI-approved terms. Open weights gives you the finished product. Open source gives you the full blueprint.
Is Meta’s Llama open source?
Llama is not open source by the OSI’s definition. OSI validated Llama 2 against OSAID criteria and found it failing on three of four axes — training code, data information, and license terms. Llama 3 and later versions were not formally validated by OSI but use a custom community license that is not OSI-approved and do not disclose training data in sufficient detail. Llama is open weights — freely downloadable and deployable, but not transparently reproducible or verifiable.
What is openwashing in AI?
Openwashing in AI is the practice of releasing only one component of an AI system — typically the model weights — while marketing the model as fully “open source.” The term is used by the Open Source Initiative to describe vendors who claim the transparency, trust, and regulatory benefits of the open source label without meeting its formal requirements. Openwashing misleads buyers about their audit rights, license freedoms, and compliance exposure.
What does the OSI’s open source AI definition require?
The OSI’s Open Source AI Definition (OSAID v1.0), published October 28, 2024, requires three components: complete training and inference code under an OSI-approved license, data information sufficiently detailed for a skilled person to reproduce the system, and model parameters under OSI-approved terms. It also requires that four freedoms be guaranteed unconditionally — use for any purpose, study, modify, and share — without having to ask permission. A model that meets only some of these requirements is open weights, not open source.
Which AI models are genuinely open source?
The AI models that passed OSI’s OSAID validation are Pythia (EleutherAI), OLMo (AI2), Amber and CrystalCoder (LLM360), and T5 (Google). OSI notes these results are part of a definitional exercise, not formal certifications. Models that failed OSI validation include Llama 2 (Meta), Grok (xAI), Phi-2 (Microsoft), and Mixtral (Mistral). The genuinely open source models are primarily research-oriented and are not the models most commonly encountered in enterprise AI procurement.
What is the Openness Audit?
The Openness Audit is a four-axis due diligence framework for B2B buyers evaluating AI vendor openness claims. The four axes are: Weights (can the model be downloaded and self-hosted?), Code (is the full training pipeline available under an OSI-approved license?), Data Information (is training data documented in sufficient detail to reproduce the system?), and License Terms (are the weights and code released under OSI-approved terms with no use restrictions?). A vendor claiming open source must pass all four axes in writing before procurement.
Does open weights AI create compliance risk for B2B companies?
Open weights AI creates compliance risk in regulated industries where explainability at the model level is required. An open weights model lets you observe outputs but does not give you visibility into the training decisions, data sources, or architectural choices that produced those outputs. If a regulator asks you to explain an AI-assisted decision at the model level, open weights alone does not satisfy that requirement. Organisations in financial services, healthcare, legal, and government verticals should assess whether their compliance framework requires open source — not just open weights — before deploying.
Can a vendor change the license on an open weights model after you have deployed it?
A vendor can change the license terms on future versions of an open weights model released under a custom license. The Llama community license, for example, is a custom document that Meta controls and can modify. An OSI-approved license such as Apache 2.0 or MIT cannot be retroactively revoked — the freedoms granted apply permanently to the version released under those terms. B2B buyers building on open weights models with custom licenses should document the license version at time of deployment and assess whether future term changes create operational or legal risk.
Why does the EU AI Act make the open weights vs open source distinction matter more?
The EU AI Act grants exemptions from several documentation and compliance obligations to “free and open source” AI systems. Vendors who market open weights models as open source may be exploiting this exemption language to reduce their own regulatory burden — and B2B buyers who cite vendor open source claims in their own compliance documentation may be inheriting a misrepresentation. Organisations operating under EU AI Act obligations should verify independently whether a deployed model meets the Act’s specific transparency conditions, rather than relying on vendor marketing language.
Is DeepSeek R1 open source?
DeepSeek R1 is open weights, not open source. DeepSeek released the model weights and published a detailed technical report describing the architecture and training approach. It did not release the full training pipeline under an OSI-approved license, did not disclose training data in sufficient detail to meet OSAID data information requirements, and its license is not OSI-approved. The technical report is more transparent than most comparable models. The “open source” label applied to it in early 2025 press coverage was not accurate by the OSI’s definition.
Conclusion
The open weights vs open source distinction is not a technical debate. It is a procurement risk that most B2B buyers are currently absorbing without knowing it.
Every major model driving enterprise AI adoption today — Llama, Mistral, DeepSeek — is open weights. None meet the OSI’s open source criteria. The vendors behind them are not hiding this fact. They are simply using language that obscures it, and the industry has not pushed back hard enough to matter.
The Openness Audit changes that calculation. Four questions, asked in writing, before any AI infrastructure contract is signed: Can we download and self-host the weights? Is the full training pipeline available under an OSI-approved license? Is the training data documented in sufficient detail to reproduce the system? Are the license terms unconditional and OSI-approved? A vendor who cannot answer all four has not released an open source model. That fact should be in your procurement record before you sign.
Openness is not binary — and open weights is genuinely valuable. But the word “open source” has a definition now. Buyers who know it are harder to mislead.
- Open Source Initiative — Open Source AI Definition v1.0, October 2024
- Open Source Initiative — Open Source AI Hub, including Combat Openwashing section, 2024
- Open Source Initiative — OSAID FAQ and Validation Results, 2024
- TechCrunch — “We Finally Have an ‘Official’ Definition for Open Source AI,” October 2024 (Maffulli quote)
- WCR Legal — Llama 3 Community License: 700M MAU Limit Analysis, 2026
- InfoWorld — “OSI Unveils Open Source AI Definition 1.0,” October 2024
- Hunton Andrews Kurth — “Open Source AI Models: How Open Are They Really?”, 2025
- International AI Safety Report — Open Weight vs Open Source Distinction, 2025
- Meta AI — Llama Downloads Milestone, March 2025





