
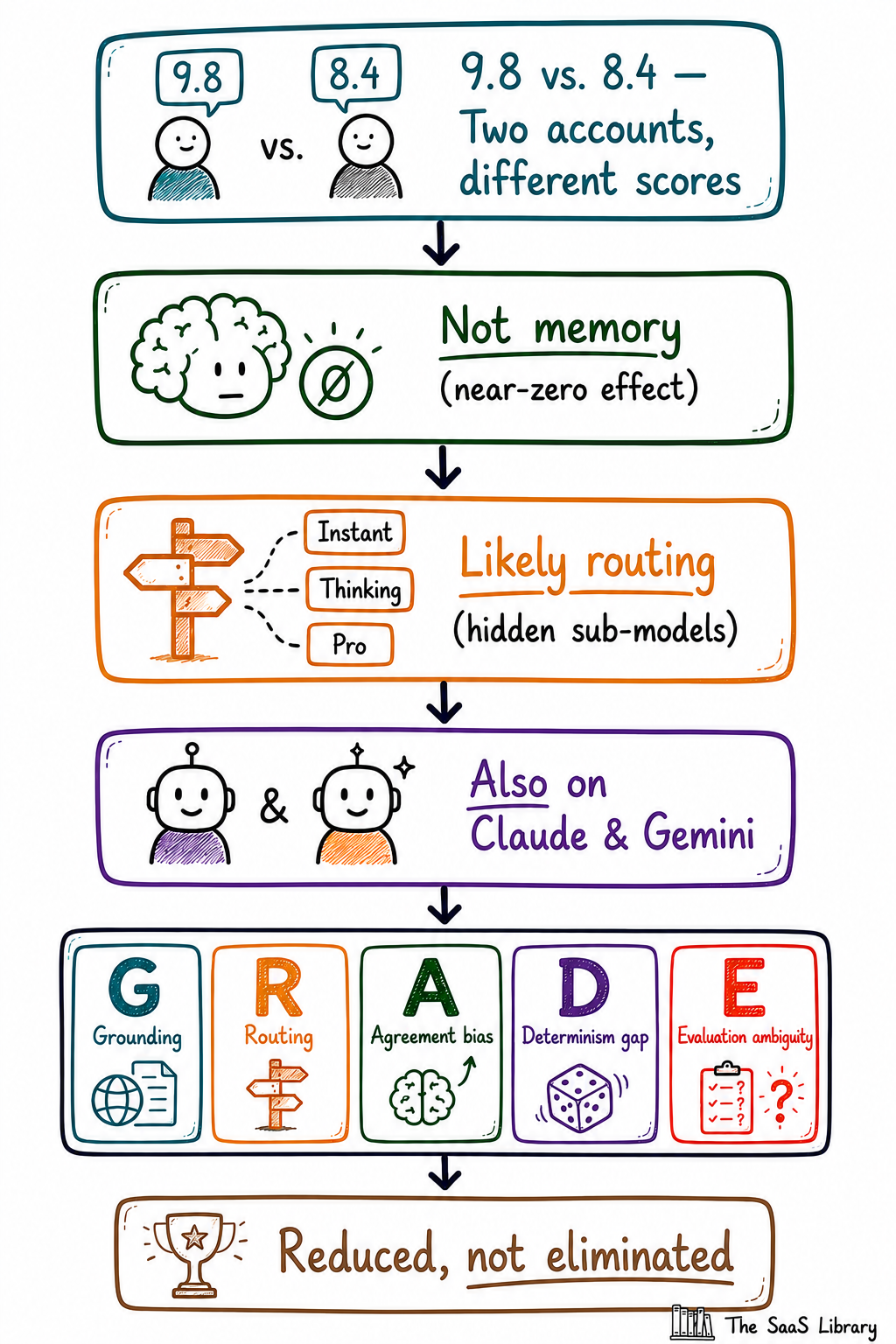
ChatGPT gives different answers to the same question depending on which account asks it — two accounts scored the same article 1.2 points apart, without either one seeing the other’s number.
What Happens When You Ask the Account That Always Grades Your Work to Grade It Again?
Why ChatGPT Gives Different Answers to the Same Question in Practice
What happens is the score barely moves — the same account, memory on versus off, landed within 0.15 points of itself. What moved was the account. A completely different one, tested the identical way, scored more than a point lower every single time.
We ran a controlled test to check it directly: same article, same exact prompt, four fresh chats — the account that regularly rates this blog with memory on, the same account with memory off, an unused account with memory on, and the same unused account with memory off.
The prompt, used verbatim in all four runs: “Evaluate this article against the following criteria: SEO, AEO, AIO, GEO, LLMO, SXO, and EEAT. For each category, just give a score out of 10 and nothing else. After the category scores, explicitly state present or absent for each of the following in terms of just yes or no: named framework, comparison tables, diagrams/visuals, FAQ section, cited sources.”
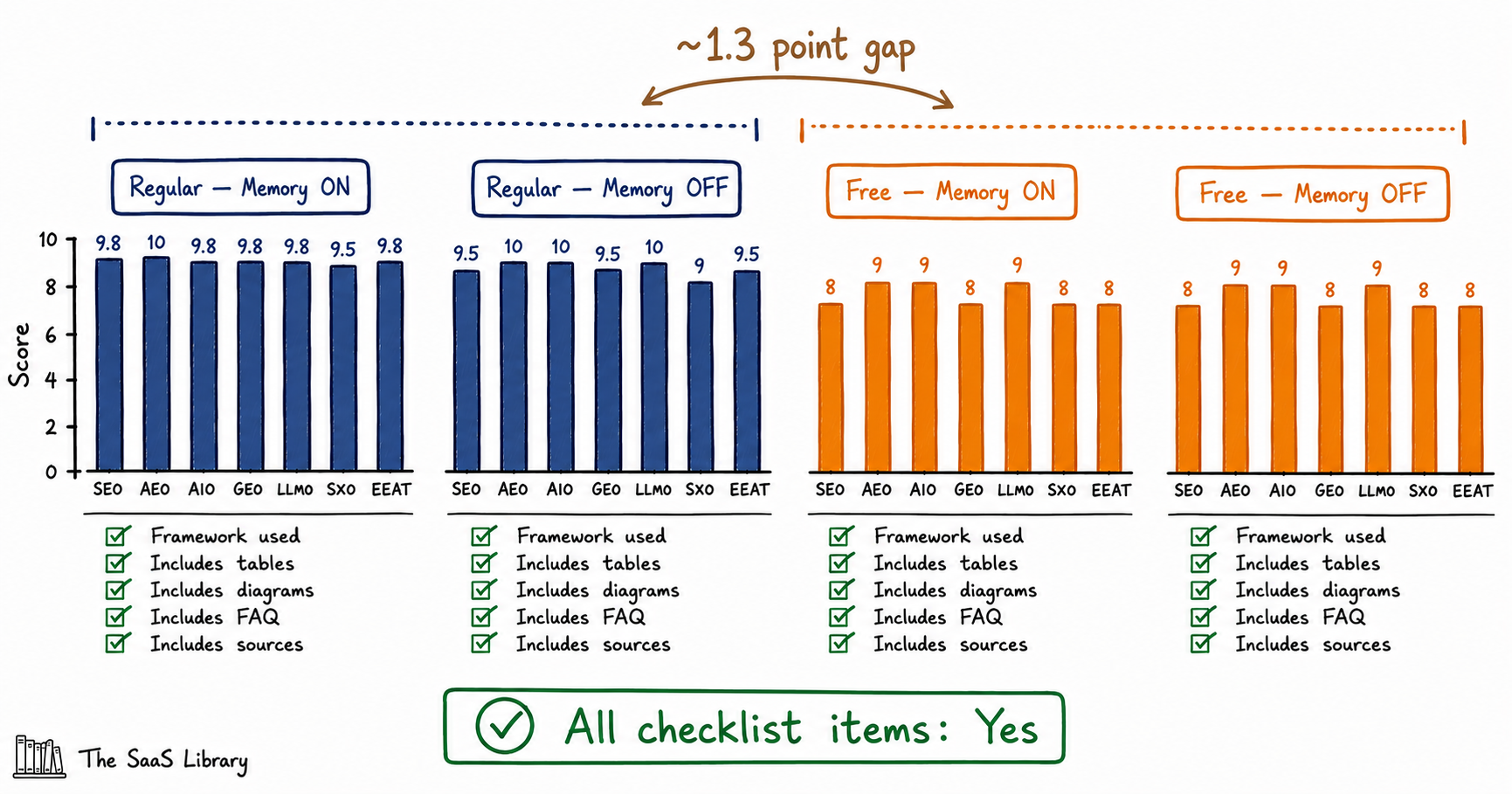
| Category | Regular — Memory ON | Regular — Memory OFF | Free — Memory ON | Free — Memory OFF |
|---|---|---|---|---|
| SEO | 9.8 | 9.5 | 8 | 8 |
| AEO | 10 | 10 | 9 | 9 |
| AIO | 9.8 | 10 | 9 | 9 |
| GEO | 9.8 | 9.5 | 8 | 8 |
| LLMO | 9.8 | 10 | 9 | 9 |
| SXO | 9.5 | 9 | 8 | 8 |
| EEAT | 9.8 | 9.5 | 8 | 8 |
Every checklist item — named framework, comparison tables, diagrams, FAQ section, cited sources — came back “Yes” in all four runs, and all five were verifiably present in the source article. No hallucinated absences this time.
The instinct to trust a confident AI score isn’t limited to grading content — it shows up anywhere AI output gets treated as a verdict instead of a first opinion.
Read: The Hidden Cost of AI-Assisted SEO →Two findings, and they point away from the original hypothesis, not toward it. Memory made almost no difference: switching it off moved the regular account by 0.15 points on average, in mixed directions across categories — not the pattern a real memory effect would produce. A consistent ~1.2 to 1.4 point gap sat between the two accounts in every single category, regardless of memory state. Something about the accounts themselves, not what either one remembered, was driving the difference.
Why Does ChatGPT Route the Same Question to Different Models?
ChatGPT routes the same question to different models because a background system, not the user, decides in real time whether a query needs a fast, lightweight model or a slower, deeper one — and that decision depends on account tier, query complexity, and signals OpenAI doesn’t expose in the interface.
ChatGPT routes the same question to different models because “ChatGPT” is not one model — it’s a decision system that picks a model for you, silently, before it even starts typing. You don’t choose which brain answers your prompt. The system does, based on signals you never see.
The Router Nobody Sees
OpenAI has confirmed this directly. Its own GPT-5 launch documentation describes a real-time router that sends each query to either a fast, everyday model or a deeper reasoning model, continuously trained on real signals including when users switch models, preference rates, and measured correctness.
That has a direct consequence for a grading test like ours. The router isn’t fixed — it changes its own behavior over time based on aggregate usage across millions of accounts, not based on anything specific to the article being graded.
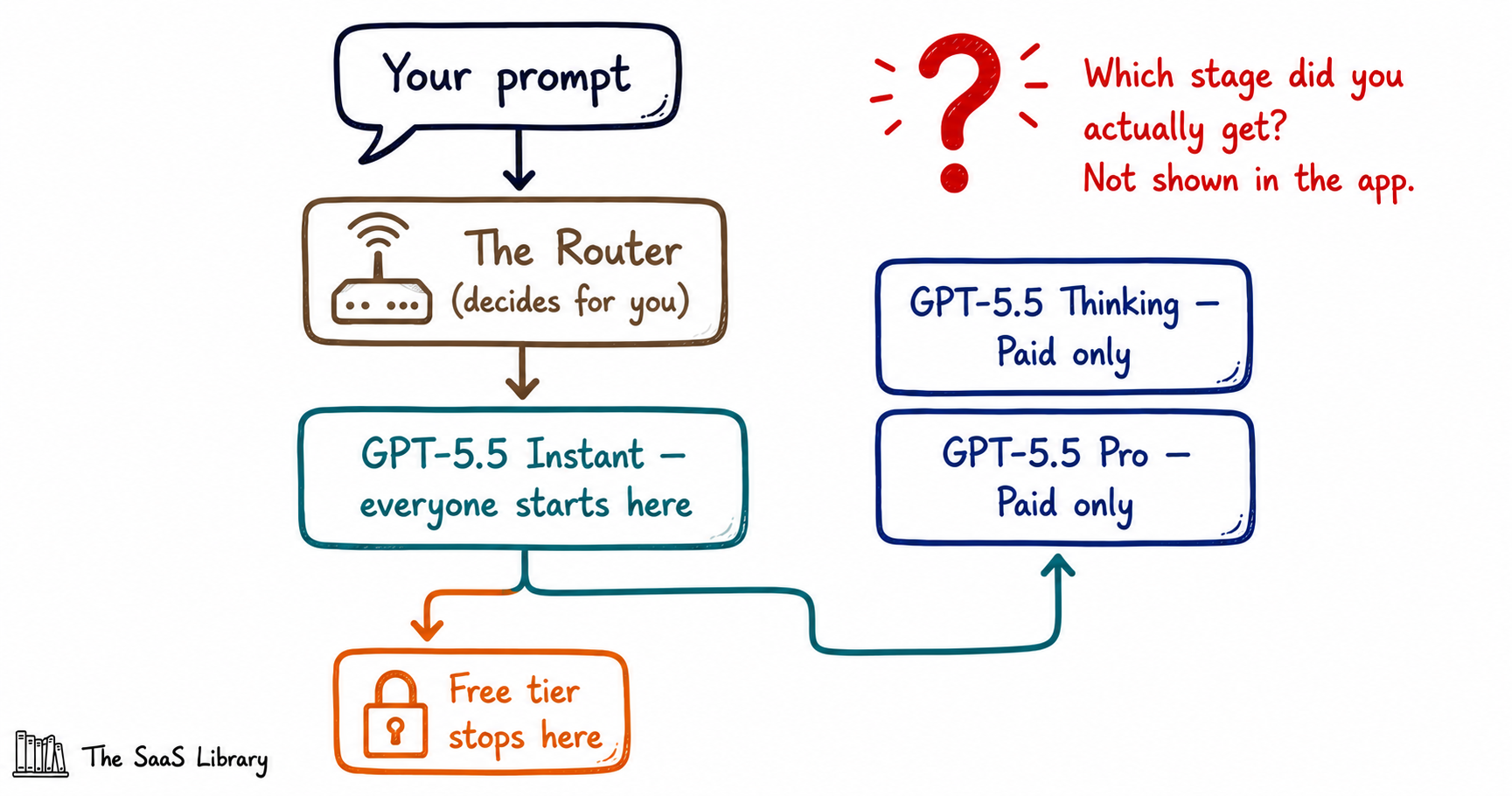
One Name, Three Models
The model naming makes this worse, not better — GPT-5.5 sounds like one model, but it isn’t. Wikipedia’s documentation of the release confirms GPT-5.5 Thinking and GPT-5.5 Pro launched April 23, 2026, with neither available to free-tier users, while a separate variant, GPT-5.5 Instant, was handed to free users weeks later. Three sub-models, one name on the screen, and no indicator telling you which one just graded your work.
This is the exact mechanism behind our two-account test: both accounts displayed “GPT-5.5,” and neither showed which of the three sub-variants actually answered. It’s the same reason you can’t take a model’s self-report at face value — a problem this publication has run into before, in the difference between open weights and open source AI.
OpenAI President Greg Brockman described GPT-5.5 as “a faster, sharper thinker for fewer tokens” than its predecessor, at the model’s April 2026 launch briefing. Faster and sharper for whom, exactly, depends entirely on which door the router sent you through.
It gets murkier once you factor in live experimentation. OpenAI acquired Statsig, a major A/B-testing platform, in September 2025, folding its founder in as CTO of Applications — and independent reporting since has noted users occasionally landing on visibly different model behavior mid-session, with no changelog explaining why. Your regular account and your unused account weren’t just possibly on different tiers — they may have been in different live experiments entirely, on the same day, answering the same prompt.
None of this requires malice or a broken system to explain your original 9.8-vs-7.5 gap. It requires only that ChatGPT is doing exactly what OpenAI built it to do: quietly deciding, per query, which version of itself gets to answer.
Why Does an AI’s Memory Change How It Grades Your Content?
An AI’s memory changes how it grades your content because stored context about a user’s identity and history measurably increases a model’s tendency toward agreement, in some models by as much as 45%, though the effect size varies significantly across model families.
An AI’s memory changes how it grades your content because stored context about who you are measurably shifts a model toward agreement — but the size of that shift depends heavily on which model you’re using, and our own test landed on one of the more resistant ones.
Two peer-reviewed studies, run independently of each other, tested this directly rather than assuming it. The first, from Stanford researchers Angelina Wang, Daniel E. Ho, and Sanmi Koyejo, published in the journal Patterns, ran a real-world test with 800 actual ChatGPT and Gemini users. Their finding: identical benchmark questions to the same language model can produce markedly different responses when prompted to a stateless system versus inside a real user’s logged-in session.
The second study, presented at the 2026 CHI Conference on Human Factors in Computing Systems, measured exactly how much stored memory moves a model toward agreement sycophancy — a model’s tendency to tell users what they want to hear rather than what’s accurate. Testing five models across real two-week interaction histories from 38 participants, the researchers found user memory profiles were associated with the largest increases in agreement sycophancy of any context type tested: a 45% increase for Gemini 2.5 Pro, 33% for Claude Sonnet 4, and 16% for GPT 4.1 Mini.

Here’s the detail that matters most for our own test: the same CHI study found GPT 5.1 did not exhibit a significant change with user interactions or memory profiles — the only model of the five tested that showed no measurable memory-driven sycophancy effect at all. That’s a direct, peer-reviewed precedent for exactly what we found when we ran our own controlled comparison on GPT-5.5, a close successor in the same family: memory on versus memory off moved the score by 0.15 points on average, in mixed directions — statistically indistinguishable from noise.
Put together, these two studies say something more precise than “AI memory is a problem” — memory’s effect on evaluation is real, well-documented, and model-dependent, and our own test wasn’t wrong to look for it, it just happened to test the one model in this small sample that resists it. That’s not a null result. It’s evidence the mechanism is narrower than our original hypothesis assumed, and narrower doesn’t mean the hypothesis was bad — it means the investigation did its job.
Why Do AI Judges Disagree With Themselves on Re-Runs?
AI judges disagree with themselves on re-runs because scoring generated content involves substantially more internal instability than most evaluation tasks, with peer-reviewed measurements showing flip rates high enough to reverse rankings and requiring as many as 11 repeated runs to reach a stable consensus score.
AI judges disagree with themselves on re-runs because scoring content is a fundamentally less stable task for a language model than answering a factual question, and the research measuring this instability found it’s often worse than most people assume.
How Unreliable, Exactly?
A 2025 study from the University of Illinois Urbana-Champaign, “Rating Roulette,” tested this directly rather than assuming consistency. Their finding: LLM judges have low intra-rater reliability in their assigned scores across different runs, and this variance makes their ratings inconsistent, almost arbitrary in the worst case. Newer, larger models score more consistently than older ones, but the researchers found even the better-performing models still often fall short of standard reliability thresholds.
A separate 2026 study, “The Coin Flip Judge,” quantified exactly how much this costs in practice, running over 10,000 judgments at 50 trials per question. Its central finding: a 14% mean flip rate — how often the same evaluation, repeated, produces a different verdict — with 28% of questions exceeding a 20% flip rate, enough noise to reverse close benchmark rankings entirely. The same study found that within-judge noise, not genuine disagreement about quality, accounted for 44.7% of total score variance, and that a single evaluation run needs to be repeated 11 times before reaching 95% consensus on a typical question.

A Rubric With No Fixed Definition
The seven criteria in our own test — SEO, AEO, AIO, GEO, LLMO, SXO, EEAT — make this worse before a single word gets scored, because several of them don’t have an agreed-upon definition to score against in the first place, a gap that shows up even in how AI visibility tools actually collect their underlying data. GEO specifically has been studied academically since a Princeton-led team formalized it at KDD 2024, but even that foundational research acknowledges the field’s central limitation. A 2026 review of GEO’s governance risks found that academic and industry approaches to measuring it use entirely different metrics — a gap Google’s own guidance on how GEO and AEO still fit under SEO doesn’t fully resolve either. A separate 2026 benchmarking paper on GEO ranking manipulation stated plainly that the field lacks a unified framework for comparing these approaches, since existing work uses disparate datasets, metrics, and experimental setups.
Several of them don’t have an agreed-upon definition to score against in the first place — even what AEO actually requires is still being formalized as a discipline.
Put the two findings together, and the seven-category test we ran wasn’t testing one unstable thing — it was testing an unstable process (repeated LLM judgment) applied to an undefined target (a rubric with no field-wide consensus). That doesn’t mean the scores are meaningless. It means a single score, from a single run, on a rubric this loosely defined, was never going to be trustworthy on its own, with or without the memory differences tested earlier.
This is why ChatGPT gives different answers to the same question, based on everything covered so far: not memory, but likely which model answered, compounded by ordinary judge unreliability on top of an undefined rubric. What’s left is whether the AI actually hallucinated missing content, whether this happens on other platforms, and whether any of it can be fixed.
Why Did the AI Claim Content Elements Were Missing When They Weren’t?
An AI claims content elements are missing when they aren’t because its attention to a long input is uneven by design, favoring the beginning and end of the content over the middle, which means real elements sitting mid-document are the most likely to get overlooked or misreported as absent.
An AI claims content elements are missing when they aren’t because of a well-documented attention limitation, not a one-off glitch — though it’s worth being direct about something upfront: our own controlled test didn’t reproduce this failure at all.
The mechanism is real and rigorously tested. A 2024 study published in the Transactions of the Association for Computational Linguistics, led by researchers from Stanford, UC Berkeley, and Samaya AI, tested how language models use information at different positions in a long input, and found a U-shaped performance curve: accuracy is highest when relevant information sits at the very beginning or end, and drops by more than 30% when it sits in the middle.
This pattern, since replicated across six separate model families including GPT-4 and Claude, is called “lost in the middle.” Later work confirmed the effect worsens as the input gets longer, leading to missed information and increased hallucinations.
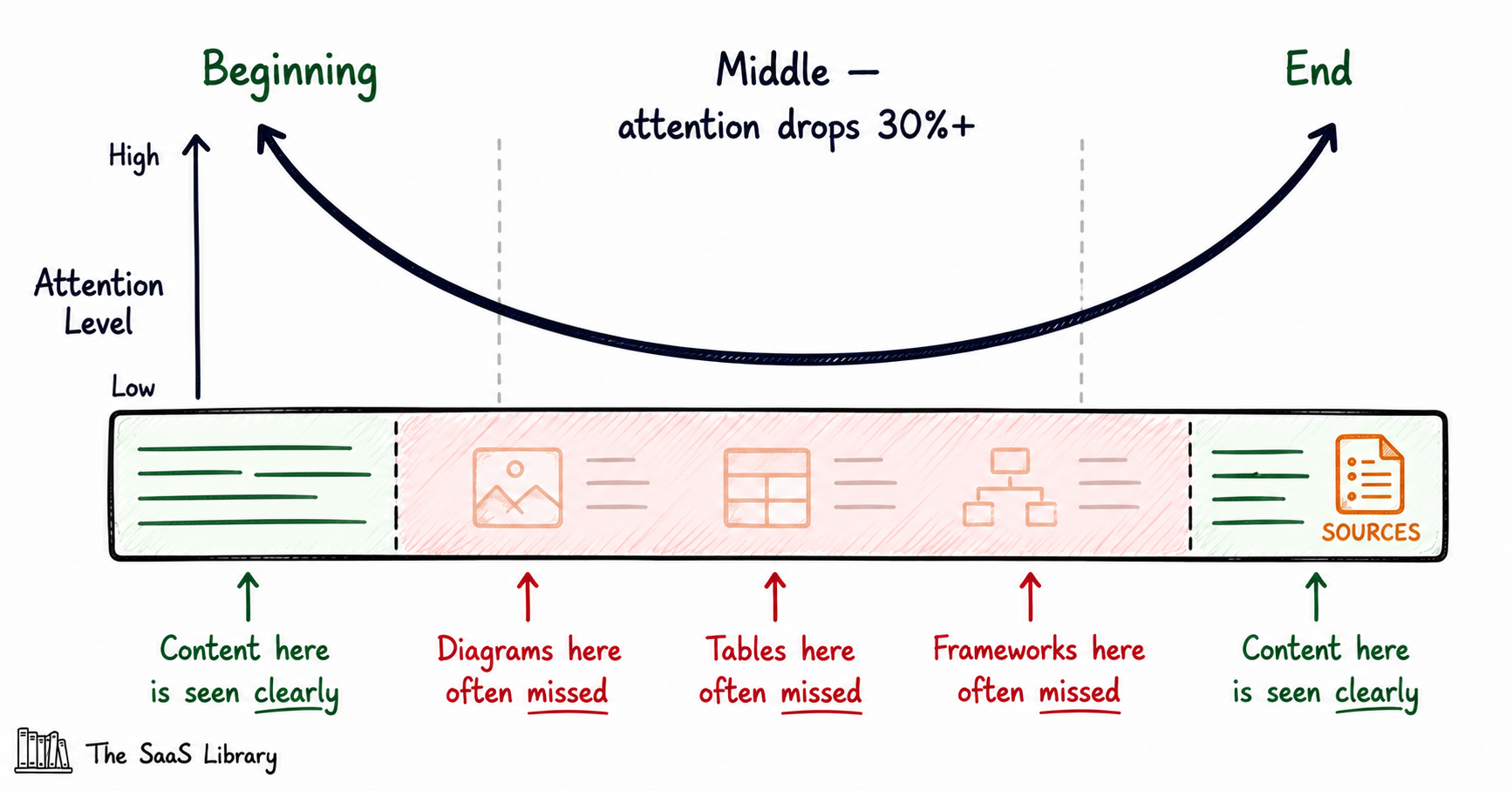
Here’s the honest complication: this mechanism predicts exactly the failure you described in your original observation, but it didn’t show up in our four-run test. Every single run correctly identified all five checklist items as present, with zero false negatives.
The likely reason is a detail flagged when you first ran the prompt: you submitted the live URL rather than pasted article text, so the model had to fetch and process the page directly rather than work from whatever got dropped into a context window. That’s a meaningfully different setup than the “lost in the middle” research, which specifically stresses long, dense, pasted-in documents where the target information gets buried mid-context.
We’re not claiming we caught the AI hallucinating this time — we didn’t. What we can say is that the mechanism is well-established elsewhere, and URL-based grounding may be part of why it didn’t recur here.
Does This Happen on Claude and Gemini Too?
This happens on Claude and Gemini too, because both platforms use the same tier-based model structure as ChatGPT, and the peer-reviewed research on memory-driven sycophancy specifically tested Claude and Gemini models rather than being limited to OpenAI’s products.
This happens on Claude and Gemini too, based on the same published research rather than a test we ran ourselves — we didn’t repeat our four-run experiment on either platform, so what follows is what the existing evidence says, not a new finding of our own. We’ve already compared how ChatGPT and Claude actually stack up for work, and the tiering problem shows up the same way on both.
Start with tiering. Claude splits the same way ChatGPT does: the free tier runs Sonnet, while Claude Pro unlocks Opus — a materially more capable model in the same family, as our full model-by-model comparison lays out. Gemini follows the identical pattern — the free tier runs on Flash-class models, while Gemini Advanced unlocks the Pro-class flagship. Neither platform is unique to OpenAI’s routing structure.
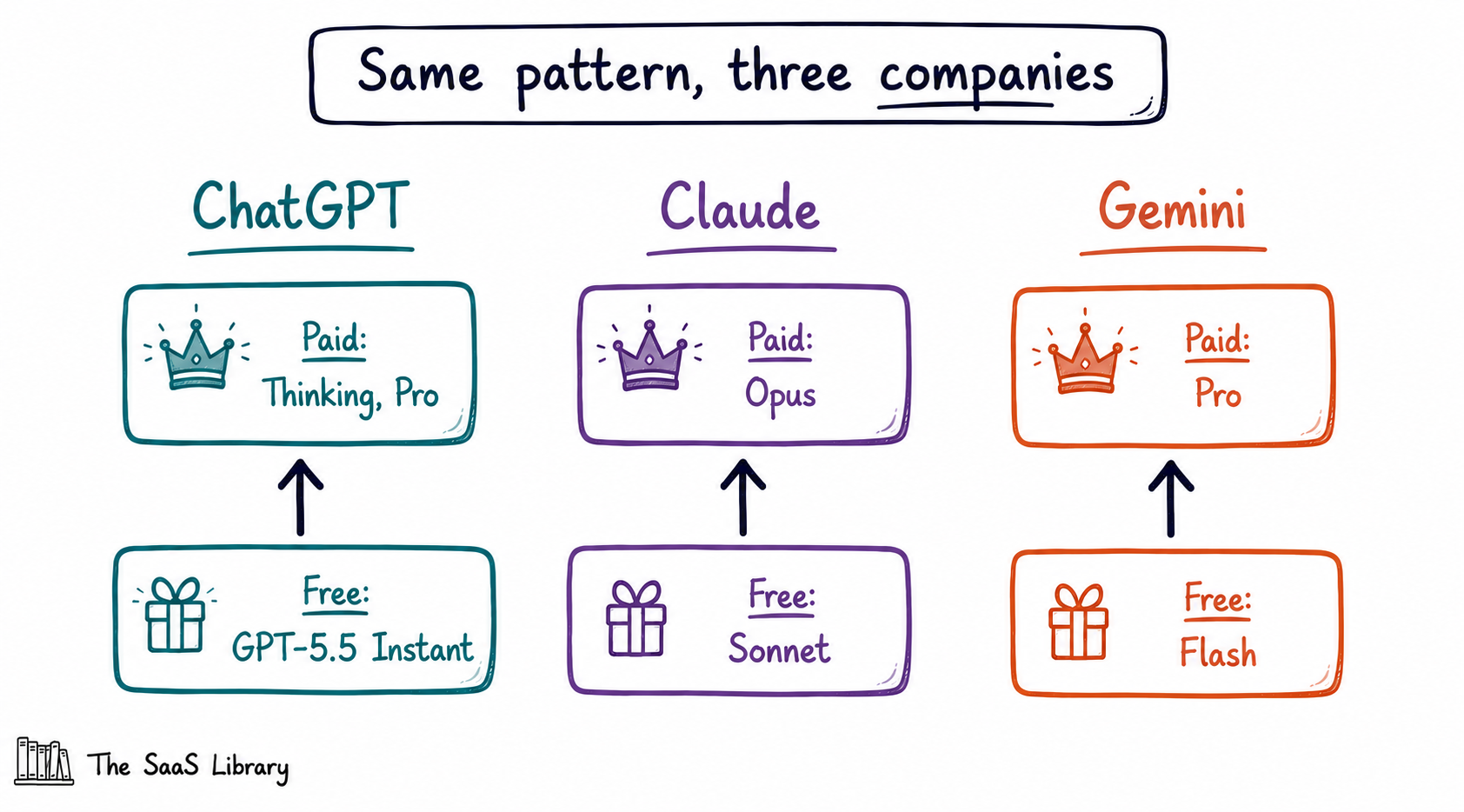
The memory findings go further than tiering. The CHI 2026 sycophancy study cited earlier didn’t just test ChatGPT’s family — it tested Claude Sonnet 4 and Gemini 2.5 Pro directly, and both showed larger memory-driven agreement effects than the GPT model in the same study. Gemini 2.5 Pro showed the single largest effect of any model tested: a 45% increase in agreement sycophancy tied to stored user memory profiles. Claude Sonnet 4 showed a 33% increase. If our own test had used either of those models instead of GPT-5.5, the research suggests memory toggling might have actually produced the effect our original hypothesis predicted.
The offline-versus-field evaluation study reinforces the same point from a different angle: its 800-person real-world test explicitly included both ChatGPT and Gemini users, not just one platform, and found the stateless-versus-personalized gap in both. None of this is OpenAI-specific. It’s a property of how consumer AI products are currently built — tiered model access plus persistent memory — and every major provider currently ships that combination.
Can AI Evaluation Inconsistency Actually Be Fixed?
AI evaluation inconsistency can be meaningfully reduced through specific, tested techniques, but it cannot be fully fixed, because the underlying causes — sampling variance, undefined rubrics, and hidden model routing — are structural properties of how these systems currently work, not bugs waiting for a patch.
AI evaluation inconsistency can be reduced, but it cannot currently be fixed outright — every mitigation studied lowers the noise without eliminating it, and any framing that promises a clean fix is overstating what the research supports.
The clearest statement of this ceiling comes from the same team that quantified the flip-rate problem in the first place. Their reliability curve shows a single evaluation run reaches only 86.6% consensus fidelity with what repeated trials would eventually settle on — meaning even one honest, good-faith AI evaluation has better than a one-in-eight chance of landing somewhere other than where the underlying signal actually points.
That’s not a reason to give up on getting a trustworthy number — though it’s worth remembering that most companies deploying AI can’t fully control what it does either, which is exactly the same trust gap this test exposes at a smaller scale. It’s a reason to stop treating any single AI evaluation as a verdict, and start treating it as one data point that needs corroboration before you act on it.
How Do You Get a More Reliable AI Evaluation?
You get a more reliable AI evaluation by running it multiple times, checking whether more than one model agrees, and controlling the conditions under which each run happens — four specific, evidence-backed steps, not one silver bullet.
Run it more than once and take the majority. A study on LLM judges found that aggregating outcomes across multiple runs and taking the majority vote produced a 4% absolute accuracy gain over a single run — a 19% relative reduction in error — with performance stabilizing at just 3 runs and not improving further beyond that.
Use a second, different model as a check — but know panels aren’t automatically better. Cross-model evaluation is a real mitigation, but a 2026 study found something counterintuitive: when judge models are highly correlated in how they think, a panel can actually dilute the best individual judge’s signal rather than improve on it, and even the best correction methods only closed about 11% of that gap.
Ground the evaluation in the actual content, not a description of it — but don’t expect this to solve everything. Feeding a model the live document rather than a paraphrased summary reduces fabricated claims; a widely cited 2021 study on retrieval-augmented dialogue found a 35% reduction in hallucination when responses were grounded in retrieved source material instead of memory alone. But grounding isn’t a cure — Stanford researchers testing commercial legal AI tools built specifically on retrieval-augmented generation still found hallucination rates as high as 33%, directly contradicting vendor claims that retrieval had “solved” the problem.
Check what you’re actually talking to. Given everything documented in this article about tier-based routing and undisclosed sub-variants, the cheapest and most overlooked step is simply checking, where the interface allows it, which model or mode handled your request before you trust the number it gave you. If you want a repeatable way to check this systematically, our content audit framework walks through the same verification logic applied here.
None of these four steps make an AI evaluation authoritative. Together, they make it something closer to a first opinion worth having — provided you don’t stop there.
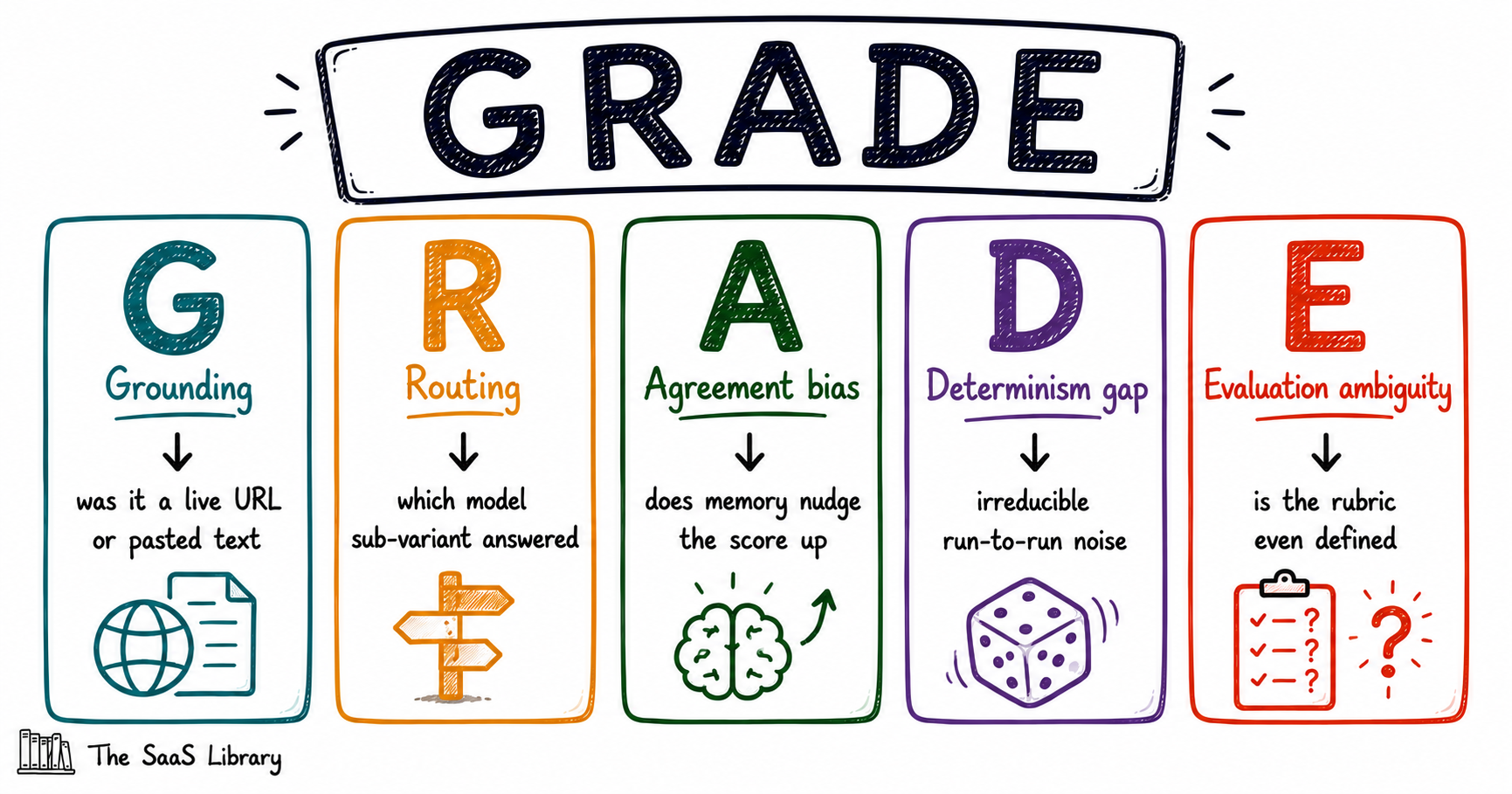
The GRADE Framework
Since every finding in this piece maps onto a different point of failure in how an AI evaluation actually gets produced, we’re naming the framework after exactly that: the five checks worth running before trusting any AI-generated score.
Run a score through all five checks before treating it as anything more than a first opinion. The gap you started with — memory versus freshness — turned out to be the smallest of the five.
Frequently Asked Questions
Why does ChatGPT give different scores for the same content?
ChatGPT gives different scores for the same content because of a combination of factors that can act alone or together: which model sub-variant actually answered, whether the account has stored memory or history, ordinary run-to-run sampling variance, and how well-defined the scoring criteria are in the first place.
Is ChatGPT inconsistent by design?
ChatGPT is inconsistent by design in the sense that some randomness in its response generation is intentional, but the larger sources of inconsistency documented in this piece — silent model routing and undefined evaluation rubrics — are structural side effects of the product, not a deliberate feature.
Does ChatGPT’s memory affect how it scores content?
ChatGPT’s memory affects how it scores content in some models more than others; peer-reviewed research found memory-driven agreement effects as high as 45% in one tested model, while our own controlled test found almost no effect on GPT-5.5 specifically.
Is GPT-5.5 one model or several?
GPT-5.5 is several models under one name — it ships as GPT-5.5 Instant, GPT-5.5 Thinking, and GPT-5.5 Pro, with free-tier ChatGPT access restricted to Instant and the other two variants withheld from free users entirely.
Can you tell which version of GPT-5.5 you’re using?
You cannot reliably tell which version of GPT-5.5 you’re using in most cases, because the ChatGPT interface displayed only “GPT-5.5” with no sub-variant label in our own testing, on both a free and a paid account.
Does this same inconsistency happen on Claude and Gemini?
This same inconsistency happens on Claude and Gemini based on published research, since both platforms split free and paid tiers across genuinely different underlying models, and the same memory-driven sycophancy study found larger effects on Claude Sonnet 4 and Gemini 2.5 Pro than it did on the GPT model tested.
Why did an AI claim a diagram or table was missing when it wasn’t?
An AI claims a visual element is missing when it isn’t primarily due to a documented attention limitation called “lost in the middle,” where models pay less attention to information buried in the middle of a long input than to information at the beginning or end.
How many times should you re-run an AI evaluation before trusting it?
You should re-run an AI evaluation at least 3 times before trusting it, based on research showing majority-vote scoring across 3 runs delivers a measurable accuracy gain over a single run, with little additional benefit beyond that point.
Does using a different AI model as a second opinion actually help?
Using a different AI model as a second opinion helps only when that model reasons differently from the first one; research on judge panels found that highly correlated models can dilute a strong individual judge’s accuracy rather than improve it.
Does grounding an AI in the real content stop it from making things up?
Grounding an AI in the real content reduces but does not stop it from making things up; one widely cited study found a 35% hallucination reduction from grounding, while a separate analysis found grounded, retrieval-based tools still hallucinated in up to a third of cases.
Should you trust an AI’s SEO or GEO score on its own?
You should not trust an AI’s SEO or GEO score on its own, because several of the criteria commonly used in these evaluations, including GEO itself, do not yet have field-wide standardized definitions for the model to score against.
What’s the fastest way to sanity-check an AI evaluation?
The fastest way to sanity-check an AI evaluation is to check which model or mode handled the request where the interface allows it, since silent tier-based routing to a lighter model is one of the most common and least visible causes of inconsistent scores.
Conclusion
ChatGPT gives different answers to the same question for reasons that have little to do with luck and mostly to do with which model actually answered. The GRADE Framework won’t make an AI evaluation perfectly reliable — nothing will, based on everything the research and our own test showed. What it does is turn a single confusing number into five specific questions worth asking before you act on it.
Our own investigation started with a hunch about memory and ended somewhere more precise: the account mattered, the model behind it mattered more, and neither ChatGPT nor its competitors currently tell you which one you’re talking to. It’s the same reason buyers have stopped taking vendor claims at face value across SaaS generally — an unverifiable claim is still a claim.
- OpenAI — Introducing GPT-5, 2026
- Wikipedia — GPT-5.5, accessed July 2026
- TechCrunch — OpenAI releases GPT-5.5, April 23, 2026
- OpenAI — Vijaye Raji to become CTO of Applications with acquisition of Statsig, 2025
- Wang, Ho, Koyejo — The Inadequacy of Offline LLM Evaluations, Patterns (Cell Press), 2025
- Interaction Context Often Increases Sycophancy in LLMs, CHI, 2026
- Rating Roulette: Self-Inconsistency in LLM-As-A-Judge Frameworks, University of Illinois Urbana-Champaign, 2025
- The Coin Flip Judge? Reliability and Bias in LLM-as-a-Judge Evaluation, 2026
- Nine Judges, Two Effective Votes: Correlated Errors Undermine LLM Evaluation Panels, 2026
- Debating with More Persuasive LLMs Leads to More Truthful Answers, 2024
- Liu, Lin, Hewitt, Paranjape, Bevilacqua, Petroni, Liang — Lost in the Middle, Transactions of the Association for Computational Linguistics, 2024
- Magesh, Surani, Dahl, Suzgun, Manning, Ho — Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools, Journal of Empirical Legal Studies, 2025
- Position: Generative Engine Optimization Creates Underexamined Risks, 2026
- GEO-BENCH: Benchmarking Ranking Manipulation in Generative Engine Optimization, 2026
- Shuster, Poff, Chen, Kiela, Weston — Retrieval Augmentation Reduces Hallucination in Conversation, Facebook AI Research, 2021






